Talk at GTC Taiwan 2018

About 2 weeks ago, I was invited to give a talk at NVIDIA’s GPU Technology Conference (GTC) Taiwan 2018 event. I think some of the contents of that talk is really worth sharing, so I’m writing a post about it.
Here are links to the video (talk in Chinese) and slides: video, slides.
The title of my talk at GTC Taiwan 2018 was “Applications of Real-time Object Detection on NVIDIA Jetson TX2”. In the talk, I discussed how my colleagues and I, at Inventec, applied object detection algorithms on JTX2 for smart city applications, such as detecting/counting vehicles and people. I further discussed how we improved inference speed of deep learning (CNN) based object detection models on JTX2. In this blog post, I’d like to share that latter part. Although I’m not able to share the source code (e.g. the TensorRT implementation of Faster R-CNN and SSD, developed by my colleagues) below, I think our results could help the readers understand what’s achievable on JTX2 in terms of object detection performance.
I myself have been working on object detection models on JTX2 since last year. In previous posts, I’ve already shared some of my experiences on DetectNet, Faster R-CNN, YOLOv2, YOLOv3 and SSD. And in the GTC presentation, I specifically talked about Faster R-CNN and SSD, because those were the models we really deployed in our intelligent video analytics (IVA) products so far.
Below are the 2 main PPT slides I shared at GTC Taiwan 2018, which summarized our experience of developing Faster R-CNN and SSD on Jetson TX2. I’m adding some additional comments here to make the points shown in the slides clearer.

Observations:
- In general, Fater R-CNN is more accurate than SSD, and could detect smaller objects better. Faster R-CNN could deal with arbitrary input image size without doing scaling down (discarding information in the original image) before processing. As a result, it is more capable of detecting smaller objects than SSD. In addition, its 2-stage design, i.e. Region Proposal Network (RPN) + Classification, helps in terms of classification accuracy. For a more formal discussion about this, please refer to the following paper published by Google’s research: Speed/accuracy trade-offs for modern convolutional object detectors.
- But Faster R-CNN is too slow for real-time applications which require high detection frame rate. Due to its 2-stage (RPN + Classification) design, Faster R-CNN consists of much more computation, and thus runs more slowly.
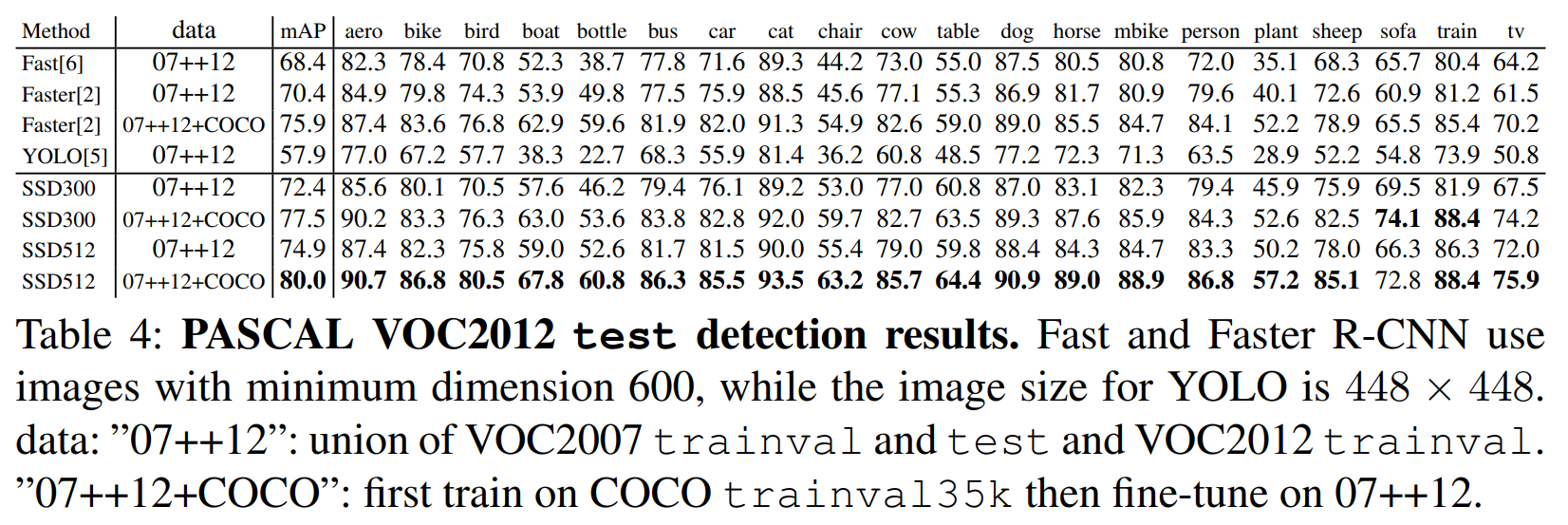
- Training an SSD model with more data does improve its mAP (object detection accuracy) significantly. For that, I’d refer the reader to the original SSD paper. Comparing the 2 “SSD300” rows in the following table, we see that we could improved mAP of the same SSD model from 72.4 to 77.5, by simply training it with more data (addiing MS COCO 2014 data into the training set).
How to improve inference speed of the object detector models:
- Replacing VGG16 CNN feature extractor with faster CNN models, such as GoogLeNet, SqueezeNet, and MobileNet. As illustrated in the next slide, this technique could be applied to both Faster R-CNN and SSD.
- Applying TensorRT to speed up our trainede models. This applies to both Faster R-CNN and SSD as well. We have successfully done that for both object detectors, with TensorRT 3.0 GA (JetPack-3.2).
- Designing the object detection models with less anchor boxes. This could probably be broken down into:
- By default, Faster R-CNN checks 300~2000 ROIs for objects, while SSD checks top 400 prior boxes. If we know there would be much less objects in the test images, we could trim down this number to reduce computation.
- If we know the objects we try to detect mostly fit to a certain aspect ratio, we could design our object detection model to use only that particular aspect ratio as the anchor/prior boxes. For example, “pedestrians” are mostly “upright”, so we could design our pedestrian detector model to use, say, only “1:2” (while discarding 1:1 and 2:1) anchor boxes or prior boxes.
- If the object we try to detect are only up to certain size (height & width), we would also be able to trim down the number of anchor/prior boxes by only keeping the ones of similar dimensions of the target objects.
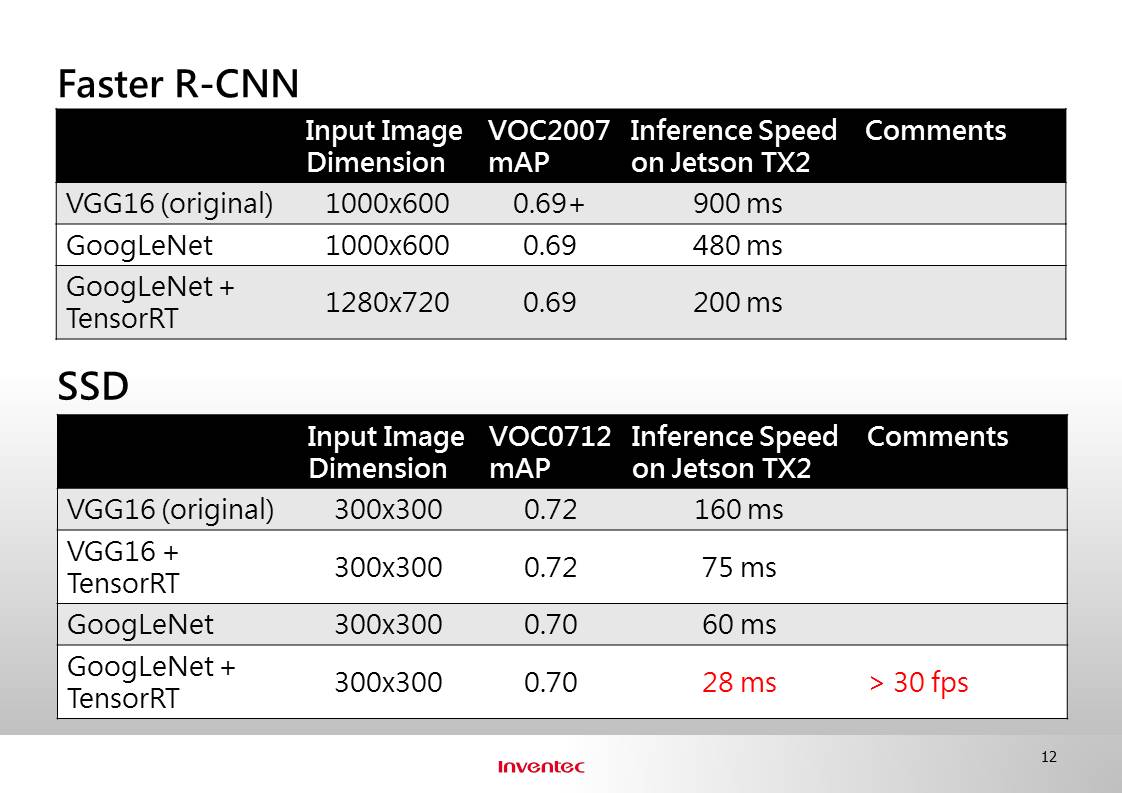
For our products, we mainly applied 2 techniques to improve inference speed of Faster R-CNN and SSD models on JTX2, while keeping similar accuracy (mAP) as the original VGG16 based model.
- Replacing VGG16 CNN feature extractor with GoogLeNet architecture.
- Applying TensorRT.
The numbers in the table above should be self-explanatory. Note that the mAP values of Faster R-CNN and SSD are for reference only. Due to difference in input image dimensions and training data, it does not present a fair comparison between the 2 object detectors.
The key point in this slide is that we were able to achieve pretty accurate object detection at >30 fps on JTX2!
As usual, I welcome comments below and would try to answer all questions there.