TensorRT YOLOv4
Quick link: jkjung-avt/tensorrt_demos
Recently, I have been conducting surveys on the latest object detection models, including YOLOv4, Google’s EfficientDet, and anchor-free detectors such as CenterNet. Out of all these models, YOLOv4 produces very good detection accuracy (mAP) while maintaining good inference speed. I think it is probably the best choice of edge-computing object detector as of today.
So, I put in the effort to extend my previous TensorRT ONNX YOLOv3 code to support YOLOv4. As usual, I shared the full source code on my GitHub repository. And I’d like to discuss some of the implementation details in this blog post.
Reference
How to Run the Demo
Please just follow the step-by-step instructions in Demo #5: YOLOv4. The steps include: installing requirements (“pycuda” and “onnx==1.9.0), downloading trained YOLOv4 models, converting the downloaded models to ONNX then to TensorRT engines, and running inference with the TensorRT engines.
After downloading darknet YOLOv4 models, you could choose either “yolov4-288”, “yolov4-416”, or “yolov4-608” for testing. I recommend starting with “yolov4-416”.
About “download_yolo.py”
The download_yolo.py script would download pre-trained yolov3 and yolov4 models (i.e. cfg and weights) from the original AlexeyAB/darknet site. It also takes care of modifications of the width and height values (288/416/608) in the cfg files.
About “yolo_to_onnx.py”, “onnx_to_tensorrt.py”, and “trt_yolo.py”
I modified the code so that it could support both YOLOv3 and YOLOv4 now.
I also verified mean average precision (mAP, i.e. detection accuracy) of the optimized TensorRT yolov4 engines. I summarized the results in the table in step 5 of Demo #5: YOLOv4.
TensorRT 7 vs. Darknet
Previously, I tested the “yolov4-416” model with Darknet on Jetson Nano with JetPack-4.4. This time around, I tested the TensorRT engine of the same model on the same Jetson Nano platform. Here is the comparison.
-
Using Darknet compiled with “GPU=1”, “CUDNN=1” and “CUDNN_HALF=1”, the “yolov4-416” model inference speed is: 1.1 FPS.
-
Using TensorRT 7 optimized FP16 engine with my “tensorrt_demos” python implementation, the “yolov4-416” engine inference speed is: 4.62 FPS.
So, the TensorRT engine runs at ~4.2 times the speed of the orignal Darknet model in this case.
YOLOv4 vs. YOLOv3
The following tables show comparisons of YOLOv4 and YOLOv3 TensorRT engines, all in FP16 mode.
In terms of mAP @ IoU=0.5:0.95: Higher is better. (Tested on my x86_64 PC with a GeForce RTX-2080Ti GPU.)
| Input Dimension | mAP of YOLOv3 | mAP of YOLOv4 |
|---|---|---|
| 288x288 | 0.331 | 0.371 |
| 416x416 | 0.373 | 0.453 |
| 608x608 | 0.376 | 0.483 |
In terms of frames per second (FPS): Higher is better. (Tested on my Jetson Nano DevKit with JetPack-4.4 and TensorRT 7, in MAXN mode and highest CPU/GPU clock speeds.)
| Input Dimension | FPS of YOLOv3 | FPS of YOLOv4 |
|---|---|---|
| 288x288 | 8.16 | 7.93 |
| 416x416 | 4.82 | 4.62 |
| 608x608 | 2.49 | 2.35 |
Major code modifications since YOLOv3
-
The output layers of YOLOv4 differ from YOLOv3. They are layers #139, #150, and #161. I added the code in yolo_to_onnx.py.
elif 'yolov4' in args.model: if 'tiny' in args.model: output_tensor_dims['030_convolutional'] = [c, h // 32, w // 32] output_tensor_dims['037_convolutional'] = [c, h // 16, w // 16] else: output_tensor_dims['139_convolutional'] = [c, h // 8, w // 8] output_tensor_dims['150_convolutional'] = [c, h // 16, w // 16] output_tensor_dims['161_convolutional'] = [c, h // 32, w // 32] -
The YOLOv4 architecture incorporated the Spatial Pyramid Pooling (SPP) module. See the example in “yolov4.cfg” below. This SPP module requires modification of the “route” node implementation in the “yolo_to_onnx.py” code. I implemented it mainly in this 713dca9 commit.
### SPP ### [maxpool] stride=1 size=5 [route] layers=-2 [maxpool] stride=1 size=9 [route] layers=-4 [maxpool] stride=1 size=13 [route] layers=-1,-3,-5,-6 ### End SPP ### -
YOLOv4 uses the “Mish” activation function, which is not natively supported by TensorRT (Reference: TensorRT Support Matrix). In order to implement TensorRT engines for YOLOv4 models, I could consider 2 solutions:
a. Using a plugin to implement the “Mish” activation;
b. Using other supported TensorRT ops/layers to implement “Mish”.
I dismissed solution #a quickly because TensorRT’s built-in ONNX parser could not support custom plugins! (NVIDIA needs to fix this ASAP…) So if I were to implement this solution, most likely I’ll have to modify and build the ONNX parser by myself. I simply don’t want to do that… (Reference: NVIDIA/TensorRT Issue #6: Samples on custom plugins for ONNX models)
Fortunately, I found solution #b was quite easy to implement. The “Mish” function is defined as
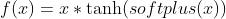 , where the “Softplus” is
, where the “Softplus” is 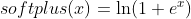 . Since “Softplus”, “Tanh” and “Mul” are readily supported by both ONNX and TensorRT, I could just replace a “Mish” layer with a “Softplus”, a “Tanh”, followed by a “Mul”. The relevant source code is in yolo_to_onnx.py:
. Since “Softplus”, “Tanh” and “Mul” are readily supported by both ONNX and TensorRT, I could just replace a “Mish” layer with a “Softplus”, a “Tanh”, followed by a “Mul”. The relevant source code is in yolo_to_onnx.py:softplus_node = helper.make_node( 'Softplus', ...... ) self._nodes.append(softplus_node) tanh_node = helper.make_node( 'Tanh', ...... ) self._nodes.append(tanh_node) inputs.append(layer_name_tanh) mish_node = helper.make_node( 'Mul', ...... ) self._nodes.append(mish_node) -
I also make the code change to support yolov4 or yolov3 models with non-square image inputs, i.e. models with input dimensions of different width and height. The relevant modifications are mainly in the input image preproessing code and the yolo output postprocessing code. As a result, my implementation of TensorRT YOLOv4 (and YOLOv3) could handle, say, a 416x288 model without any problem.
Thoughts
Previously, I thought YOLOv3 TensorRT engines do not run fast enough on Jetson Nano for real-time object detection applications. Based on my test results, YOLOv4 TensorRT engines do not run any faster than YOLOv3 counterparts. However, since mAP of YOLOv4 has been largely improved, we could trade off accuracy for inference speed more effectively. For example, mAP of the “yolov4-288” TensorRT engine is comparable to that of “yolov3-608”, while “yolov4-288” could run 3.3 times faster!!
In addition, the yolov4/yolov3 architecture could support input image dimensions with different width and height. And my TensorRT implementation also supports that. So, it is easy to customize a YOLOv4 model with, say, 416x288 input, based on the accuracy/speed requirements of the application. (Note the input width and height of yolov4/yolov3 need to be multiples of 32.)
Overall, I think YOLOv4 is a great object detector for edge applications. I’m very thankful to the authors: Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao, for their outstanding research work, as well as for sharing source code and trained weights of such a good practical model.