Running TensorRT Optimized GoogLeNet on Jetson Nano
Quick link: jkjung-avt/tensorrt_demos
In this post, I’m demonstrating how I optimize the GoogLeNet (Inception-v1) caffe model with TensorRT and run inferencing on the Jetson Nano DevKit. In particular, I use Cython to wrap C++ code so that I could call TensorRT inferencing code from python.
Reference
- How to Capture Camera Video and Do Caffe Inferencing with Python on Jetson TX2
- Trying out TensorRT on Jetson TX2
- Building And Running GoogleNet In TensorRT
- TensorRT Developer Guide
- Cython’s Documentation
Running the Demo Code
Please refer to README.md in my jkjung-avt/tensorrt_demos repository for the steps to set up and run the trt_googlenet.py program. In short, you need to make sure you have TensorRT and OpenCV properly installed on the Jetson Nano, then you just clone the code from my GitHub repository and do a couple of make’s.
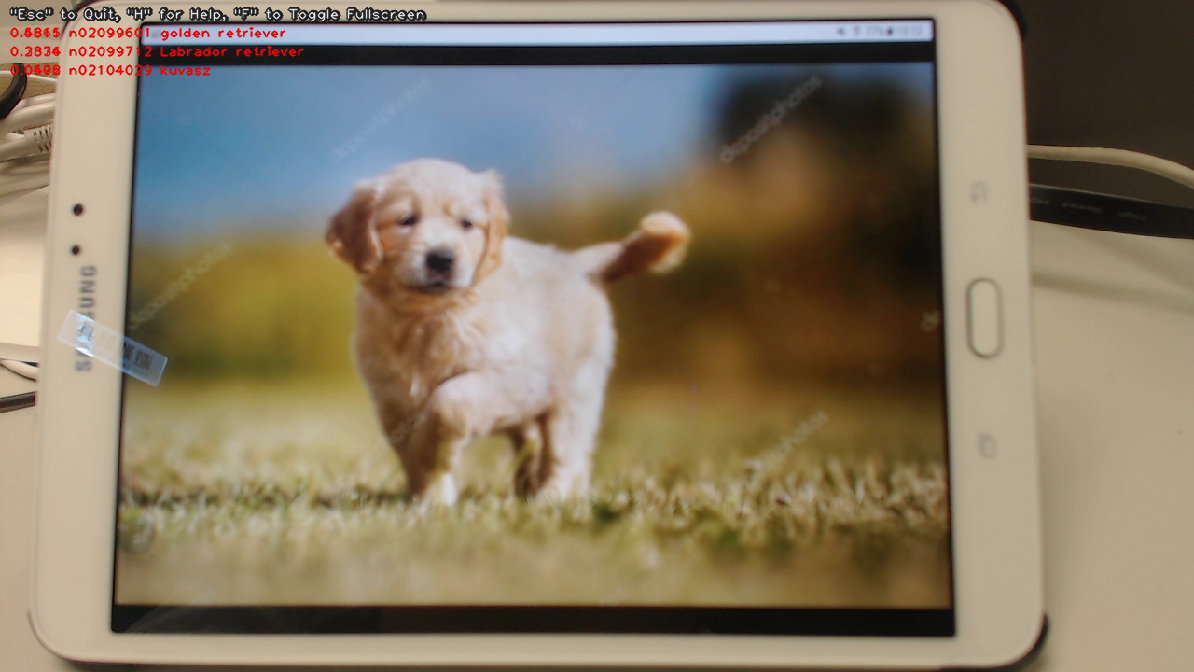
When I tested it with a USB webcam (aiming at a picture shown on my Samsung tablet), I was able to see the picture classified correctly by the TensorRT GoogLeNet as: 1. ‘golden retriever’ (0.68), 2. ‘Labrador retriever’ (0.23), 3. ‘Kavasz’ (0.05).
$ cd ${HOME}/project/tensorrt_demos
$ python3 trt_googlenet.py --usb 0 --width 1280 --height 720
Furthermore, I observed that it took the TensorRT GoogLeNet ~16ms to inference each image. I also tested the same model with caffe as below. The average forward time was ~52ms. So TensorRT (using FP16 mode) managed to speed up this model by roughly 3 times.
$ {HOME}/project/ssd-caffe/build/tools/caffe time --gpu 0 --model ${HOME}/project/tensorrt_demos/googlenet/deploy.prototxt
Discussions
-
I developed my C++ code in this demo mainly by referencing TensorRT’s official GoogLeNet sample. Full C++ source of this sample code could be found at
/usr/src/tensorrt/samples/sampleGoogleNeton the Jetson Nano DevKit. -
TensorRT Python API is not available on the Jetson platforms. I used Cython to wrap TensorRT C++ code, so that I could call them from python. For more details, please refer to Cython’s Documentations.
-
If you’d like to adapt my TensorRT GoogLeNet code to your own caffe classification model, you probably only need to make the following changes:
- Make a copy of the
googlenet/directory and rename it. Replace thedeploy.prototxtanddeploy.caffemodelwith your own model. Also replacesynset_words.txtso that the list of class names match your model. - In
trt_googlenet.py, modify the following global variables:DEPLOY_ENGINE: name of the TensorRT engine file used for inferencing.ENGINE_SHAPE0: shape of the inputdatablob; you need to modify it if your model is using a input tensor shape other than 3x224x224.ENGINE_SHAPE1: shape of the outputprobblob; you need to modify it ifoutput of your model is not 1,000 classes.RESIZED_SHAPE: for resizing of input images from camera; this should matchENGINE_SHAPE0.
- Make a copy of the
-
Running this TensorRT optimized GoogLeNet model, Jetson Nano was able to classify images at a rate of ~16ms per frame. So if the video processing pipeline is done properly, we could achieve ~60FPS with this model on the Nano. I think this is pretty great.
-
I tried to find some official benchmark numbers to verify my own test result. The closest thing I was able to find is this NVIDIA Developer Blog, Jetson Nano Brings AI Computing to Everyone, by Dustin Franklin. I extract some numbers from that blog post and make the comparison table below. (Note the numbers are all for Jetson Nano.)
Model Framework Tested by MobileNet-v2 (300x300) TensorFlow NVIDIA 64 FPS Inception V4 (299x299) PyTorch NVIDIA 11 FPS GoogLeNet (224x224) Caffe JK Jung 60 FPS -
I also tested this TensorRT GoogLeNet code on Jetson TX2. Again, I tested inferencing using either caffe or TensorRT. Comparing the TensorRT result on Jetson TX2 (140 FPS), Jetson Nano (60 FPS) did pretty OK in this case…
Platform Inference with Infer Time FPS Jetson TX2, JetPack-3.3 Caffe 27.7 ms 36 TensorRT 7 ms 140 Jetson Nano, JetPack-4.2 Caffe 52.0 ms 19 TensorRT 16 ms 60
Closing Words
I used to find NVIDIA’s documentations and sample code for TensorRT not very easy to follow. I was also a little bit frustrated that NVIDIA did not make TensoRT’s Python API available for the Jetson platforms. With this Cython approach, I am now able to harness the good CNN inferencing performance of the Jetson’s.
As always, I spent a lot of time developing this code. I’m sharing it because I believe it could benefit peer developers quite a bit. I welcome comments in Disqus below. I also welcome “stars” on my GitHub repository very much. Do give me feedbacks so that I could do better in the future.
I plan to share some more TensorRT demo examples in my jkjung-avt/tensorrt_demos repository later on. So stay tuned…
Update: I’ve added 2 blog posts about TensorRT optimized MTCNN face detector. Be sure to check them out.