Optimizing TensorRT MTCNN
Quick link: jkjung-avt/tensorrt_demos
A few days ago, I posted my first implementation of TensorRT MTCNN face detector and a corresponding blog post on GitHub. Soon after, a reader (tranmanhdat) informed me that my implementation did not run faster than another TensorFlow (not optimized by TensorRT) implementation on Jetson Nano. I had some idea about why my code was not optimal in terms of speed. So I did some analysis, and optimized the code afterwards. In the end, I was able to improve overall performance of my TensorRT MTCNN demo program by 30~40%. For example, frames-per-second (FPS) number improved from 5.15 to 6.94 (~35% faster) when I tested the same Avengers picture on Jetson Nano. Let me describe how I optimize the code in this post.
Reference
Some simple ideas for improving TensorRT MTCNN speed
-
As tranmanhdat already pointed out, using a larger ‘minsize’ helps to reduce computation and thus could speed up the detector. I think a larger ‘minsize’ reduces computation for PNet in 2 regards: (1) reducing input/output blob dimensions; (2) reducing total number of ‘scales’ (in PNet image pyramid) to be inferenced. For the blob dimension part, say, we do MTCNN face detection using a 1280x720 input image and with ‘minsize’ set to 40. Then the input blob dimension (NCHW) of the 1st scale is 1x3x216x384 (calculation below).
720 * 12 / 40 = 216 1280 * 12 / 40 = 384But if ‘minsize’ is set to 120 instead, the input blob dimension of the 1st scale is reduced to 1x3x72x128. This reduces calculation in all PNet CNN layers by at least 9 fold.
720 * 12 / 120 = 72 1280 * 12 / 120 = 128So if you are sure you don’t need to detect small faces in the images, increasing ‘minsize’ is definitely a good way to optimize the detector.
-
In case the number of faces to be detected in input images is limited to say 1 or 2 faces, e.g. for access control applications (typically with facial recognition), you could set a much lower ‘max_batch_size’ for TrtRNet and TrtONet. So the RNet and ONet engines would be built/optimized with a lower batch size and could run faster in such cases.
-
Otherwise, you might try to use a larger ‘factor’ value in TrtPNet.detect(), as an attempt to reduce total number of ‘scales’ in PNet detection. For example, I’ve tried the value
0.68and it seemed to work OK for all images I tested. But be aware that therecall(how well it recovers faces in the image) of the detector might suffer if this value is set improperly (too small).
With the above being said, they are not my focus of this writing though. I analyzed my old code and implemented some more general optimization. Please read on.
Analysis
I used python’s cProfile to check my old code. Here are the steps.
$ cd ${HOME}/tmp
$ git clone https://github.com/jkjung-avt/tensorrt_demos.git
$ cd tensorrt_demos
### checkout 2019-09-30 snapshot of the code
$ git checkout 075cb3988368563f9df06fb668da51926c98ee4e
$ cd mtcnn
$ make
$ ./create_engines
$ cd ..
$ make
$ python3 -m cProfile -s cumtime \
trt_mtcnn.py --image ${HOME}/Pictures/avengers.jpg
I let the program run for about 1 minute and collected the result.
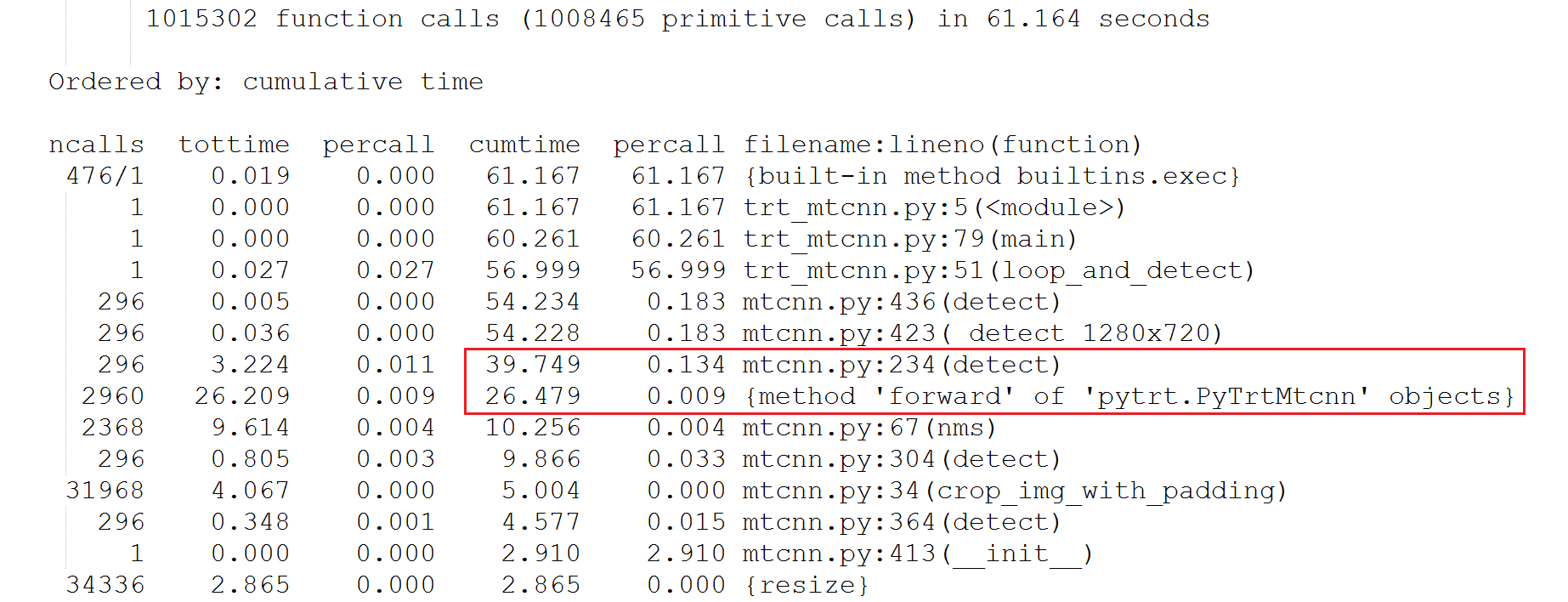
Looking at the cProfile result, I could confirm that, within the ~61 seconds of total run time, the program spent 39.7 seconds in TrtPNet.detect() function. Furthermore, the majority of the time (26.5 seconds) there was spent on the forward() call (inferencing with TensorRT PNet/det1 engine). So it was obvious that TrtPNet.detect() should be my primary target of optimization.
On the other hand, I wasn’t too surprised with the cProfile result. My old TrtPNet.detect() code reads like this:
# do detection at each scale
for scale in scales:
hs = int(np.ceil(img_h * scale))
ws = int(np.ceil(img_w * scale))
im_data = np.zeros((1, 3, 216, 384), dtype=np.float32)
im_data[0, :, :hs, :ws] = \
cv2.resize(img, (ws, hs)).transpose((2, 0, 1))
out = self.trtnet.forward(im_data)
......
Since TensorRT PNet engine could only be built with pre-determined (fixed-sized) input and output blobs, I had to pad all smaller/scaled-down images and do inferencing on them in 1x3x216x384. And there are a lot of wasted computations (computation on padded zeroes) there!
How to optimize TrtPNet
After identifying what needed to be optimized most and possible main cause of excessive computations, I tried to solve it in a straightforward way. Simply put, I tried to stack all scales of input images vertically together into 1 big image/blob, and only do PNet inferencing once. The stacked image looked like this. (Note the following is one single image I feed into PNet.)

More specifically, I computed the vertical offsets for stacking all scaled-down images. Please refer to mtcnn/det1_relu.prototxt for my calculation. And I determined that I need an input blob of 1x3x710x384 to fit all scales of images. In addition, I modified util/mtcnn.py to resize the input image and do stacking first, to call forward() (inferencing) only once before processing the output based on the proper offsets.
# stack all scales of the input image vertically into 1 big
# image, and only do inferencing once
im_data = np.zeros((1, 3, 710, 384), dtype=np.float32)
for i, scale in enumerate(scales):
h_offset = self.input_h_offsets[i]
h = int(img_h * scale)
w = int(img_w * scale)
im_data[0, :, h_offset:(h_offset+h), :w] = \
cv2.resize(img, (w, h)).transpose((2, 0, 1))
out = self.trtnet.forward(im_data)
# extract outputs of each scale from the big output blob
for i, scale in enumerate(scales):
......
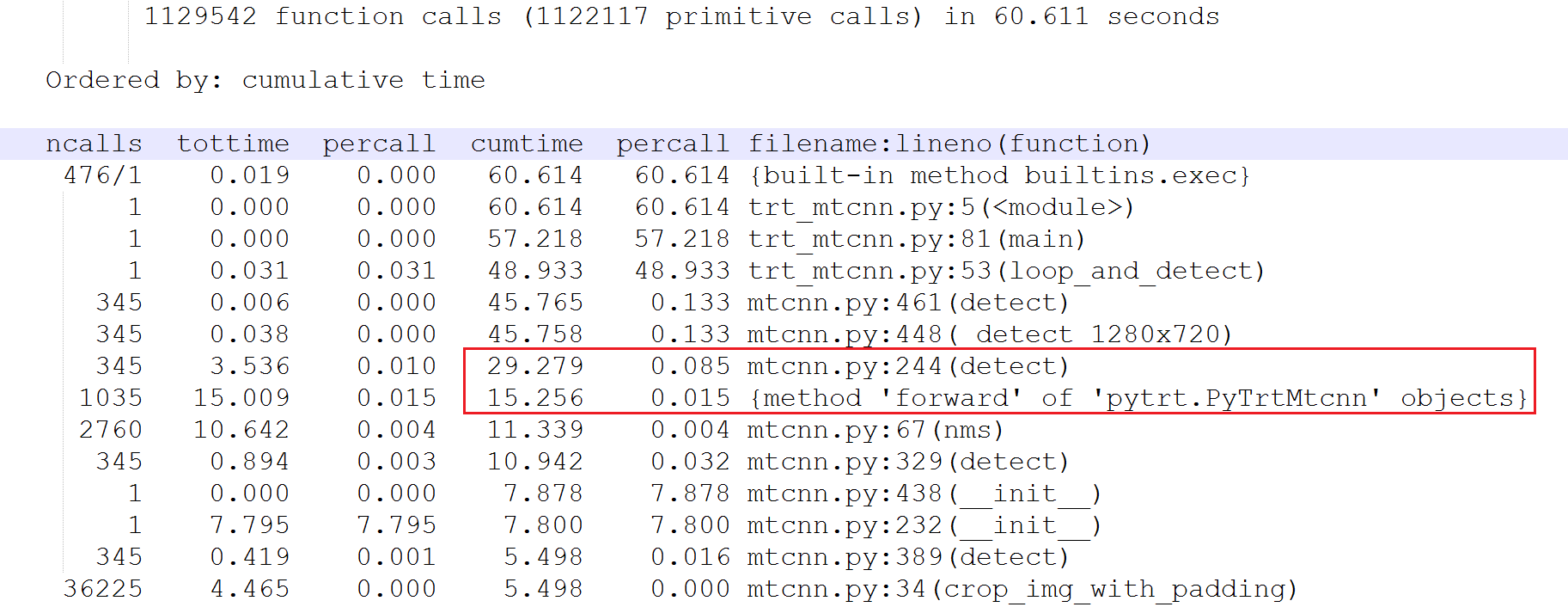
I tested the new implementation. The result was 30~40% improvement. And I ran the profiler for roughly 1 minute again.
$ python3 -m cProfile -s cumtime \
trt_mtcnn.py --image ${HOME}/Pictures/avengers.jpg
Comparing how much percentage of time the program spent in TrtPNet.detect(), I could see that it improved from 65% to 48.3%. (p.s. 39.749 / 61.164 = 56%, 29.279 / 60.611 = 48.3%) Although this function still took a lot of time to run, it was indeed much improved.
Conclusion
So there you have it. This is how and what I have done to improve my TensorRT MTCNN face detector implementation. In summary, the improvements are:
- Since I stacked scaled-down images together, the wasted computation (padded zeroes) was greatly reduced.
- In the new implementation, I only need to call TensorRT PNet/det1
forward()once. This reduces back-and-forth copying of data between GPU and CPU. - Cache performance might also be improved a little in
TrtPNet.detect(), since in theforloops we repeat accessing the same piece of memory.
You might ask: Can my implementation be improved further? Absolutely. Looking at the CProfile log, we could see that the demo program also spends a lot of time running python implementations of ‘nms’ (Non-Maximum Suppression) and ‘image cropping’, etc.. Those functions are called very frequently (dozens of times per image frame) in the code. I could imagine that python’s type checking and object unpacking occupying a significant portion of time in those functions. So if I were to optimize the code further, my approach should be to optimize those python functions by re-writing them with either C++ or Cython.