TensorRT MTCNN Face Detector
Quick link: jkjung-avt/tensorrt_demos
It has been quite a while since I first created the tensorrt_demos repository. I set out to do this implementation of TensorRT optimized MTCNN face detector back then, but it turned out to be more difficult than I thought. Anyway, I finally got it to work. I tested the code with this Avengers poster on my Jetson Nano. I got roughly 5.15 frames per second (FPS), and it did detect most of the faces in the picture. (Interestingly, the robotic face of Nebula at the bottom-right corner was correctly detected, while the face of Wong at the bottom was missed by the model.)
{kind=link}

I’m going to discuss some of the decisions I made when implementing this TensorRT MTCNN.
Reference
- Running TensorRT Optimized GoogLeNet on Jetson Nano
- MTCNN paper and implementation by the original author: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
- For working around the problem of TensorRT not supporting ‘PReLU’ layers: PKUZHOU/MTCNN_FaceDetection_TensorRT
Running the Demo Code
Please refer to README.md in my jkjung-avt/tensorrt_demos repository for the steps to set up and run the trt_mtcnn.py program. Note that the code supports various kinds of image/video inputs. So you should be able to try the following.
$ cd ${HOME}/project/tensorrt_demos
#
### Using an image file for testing
$ python3 trt_mtcnn.py --image ${HOME}/Pictures/avengers.jpg
#
### Using a video file
$ python3 trt_mtcnn.py --video test_video.mp4
#
### Using a USB webcam
$ python3 trt_mtcnn.py --usb 0 --width 1280 --height 720
#
### Using an IP CAM (RTSP stream)
$ python3 trt_mtcnn.py --rtsp rtsp://admin:123456@192.168.1.64/live.sdp
Discussions
I try to discuss the trickier parts of TensorRT MTCNN and some of my design decisions in the implementation here. Feel free to leave comments/questions below. I’ll add stuffs here if needed.
-
MTCNN is a pretty popular face detector. Unlike RCNN, SSD or YOLO, MTCNN is a 3-staged detecor. The 1st stage of MTCNN, i.e. PNet, applies the same detector on different scales (pyramid) of the input image. As a result, it could generalize pretty well to target objects (faces) at various sizes and it could detect rather small objects well. The 2nd and 3rd stages of MTCNN, aka RNet and ONet, only learn to classify outputs of the previous stage and could produce very good/accurate results. In my opinion, MTCNN works in a similar way as XGBoost. I think its design is quite elegant.
-
The original MTCNN face detector models were implemented with Caffe and were using ‘PReLU’ layers. Since the TensorRT library on Jetson Nano/TX2 did not support parsing ‘PReLU’ layers directly from the prototxt/caffemodel files and I did not want to implement/debug the plugin layer either, I chose to use PKUZHOU’s workaround. In short, PKUZHOU converted all PReLU layers into ‘2 branches of ReLU layers’. (I’ve verified that the weights in scale1_2 layer matched weights in the original PReLU1 layer.) As a result, the converted Caffe models could be directly parsed and optimized by TensorRT API.
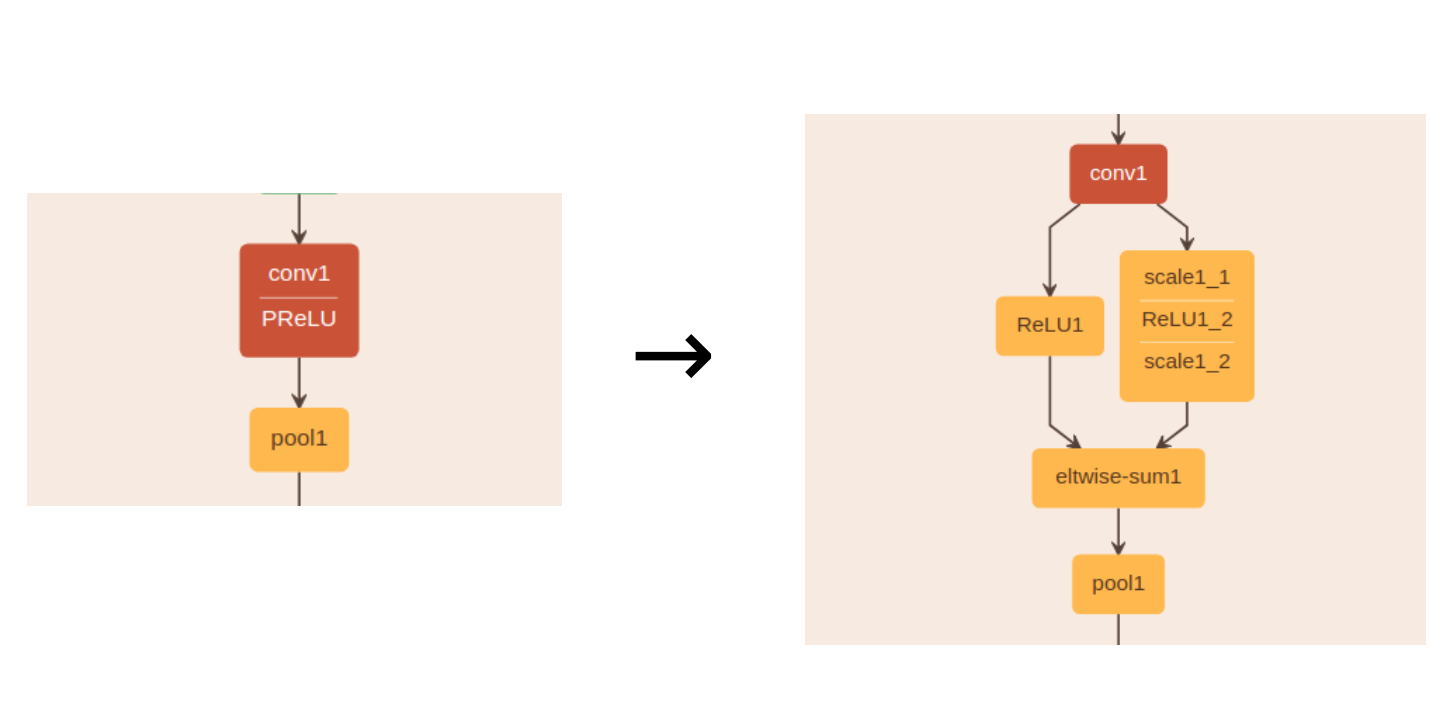
-
I used Cython to wrap TensorRT C++ code, so I could do inferencing of TensorRT optimized MTCNN models and implement the rest of MTCNN processing in python. Please refer to my earlier post, Running TensorRT Optimized GoogLeNet on Jetson Nano , for more information about Cython.
-
TensorRT, as of version 5.x or earlier, only supports fixed-sized blobs. That is, all blob sizes need to be explicitly specified when the TensorRT engine is built. So I made the following design decisions:
- Maximum input image size is 1280x720. If the image is too large, I would resize it (while keeping the aspect ratio) to fit 1280x720. Refer to source code around this line for details.
- Minimum detection size (‘minsize’) is set to 40. That means, if the image size is within 1280x720, the TensorRT MTCNN should be able to detect all faces larger than 40x40.
- Based on the above, I could calculate and set input and output blob sizes in the code. Please refer to det1_relu.prototxt for my calculation. For input images smaller than 1280x720 (which corresponds to input blob size of 384x216), I’d just pad the image with 0 and still use the pre-determined input blob size for inferencing. I did the same for the smaller images in the ‘pyramid’.
- If you’d like to modify the code to support larger input images or a different ‘minsize’, you’ll have to modify the prototxt and source code:
- Recalculate and modify input blob dimension in det1_relu.prototxt. Make sure blob sizes are correct when you run ‘create_engines’.
- Modify TrtMtcnn.detect() to support larger input images properly.
- Modify blob sizes in TrtPNet.__init__().
- Modify ‘minsize’ in TrtPNet.detect().
- Modify shape of the padded numpy array of PNet input.
-
For RNet and ONet, I need to decide a ‘maximum batch size’ when building the TensorRT engines. If the value is set too large, the TensorRT engines might run too slowly. But I cannot set a value which is too small, because it would limit the maximum number of faces the model could detect in the input image. I end up using 256 and 64 as the max batch sizes for RNet and ONet respectively. The values are hard-coded in both create_engines.cpp and mtcnn.py. As a result, my implementation would not be able to detect more than 64 faces in the input image.
In addition to the above, there are still numerous details in the python code implementation of MTCNN. I might talk about them in a later post…
Update: I’ve added a blog post about how I optimized the code and made TensorRT MTCNN run faster: Optimizing TensorRT MTCNN