Trying out TensorRT on Jetson TX2
2019-05-20 update: I just added the Running TensorRT Optimized GoogLeNet on Jetson Nano post. It demonstrates how to use mostly python code to optimize a caffe model and run inferencing with TensorRT.
NVIDIA provides a high-performance deep learning inference library named TensorRT. It could be used to speed up deep learning inference (measured as frames per second) on Jetson TX2, comparing to say the origial caffe+cudnn, by a few times. At the time of this writing, TensorRT-2.1.2 is available for Jetson TX2, and is automatically installed with JetPack-3.1. Meanwhile, a latest version of the TensorRT documentation could be found at: http://docs.nvidia.com/deeplearning/sdk/tensorrt-user-guide/index.html
As I was learning to use TensorRT on Jetson TX2, I wanted to make sure I could use TensorRT to speed up the deeplearning-cats-dogs-tutorial model I trained on Jetson TX2 previously. So I first downloaded and ran the jetson-inference code on Jetson TX2.
$ mkdir -p ~/project
$ cd ~/project
$ git clone https://github.com/dusty-nv/jetson-inference.git
$ cd jetson-inference
$ mkdir build
$ cd build
$ cmake ..
$ make -j4
$ cd aarch64/bin
$ ./imagenet-camera googlenet
I also modified jetson-inference/imagenet-camera/imagenet-camera.cpp by defining DEFAULT_CAMERA to 1 (using /dev/video1), so I could use my own USB camera, Logitech C920, for testing.
After I verified the jetson-inference code was running OK on my Jetson TX2, I tried to feed my previously trained deeplearning-cats-dogs-tutorial AlexNet model into TensorRT for testing. For that, I also needed to create a classes.txt which specifies the name of class 0 as ‘cat’ and class 1 as ‘dog’. A copy of my trained model could be found below:
$ cd ~/project/jetson-inference/build/aarch64/bin/
$ ./imagenet-camera \
-model /home/nvidia/project/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2/caffe_model_iter_40000.caffemodel \
-prototxt /home/nvidia/project/deeplearning-cats-dogs-tutorial/caffe_models/caffe_model_2/caffenet_deploy_2.prototxt \
-labels classes.txt -input_blob data -output_blob prob
The result was pretty OK and as expected. Referring to the screenshot below, the program correctly classified the image from USB camera as ‘dog’. The model, which was similar to AlexNet, ran in FP16 mode and could process/render 25~30 fps of 1280x720 images on Jetson TX2.
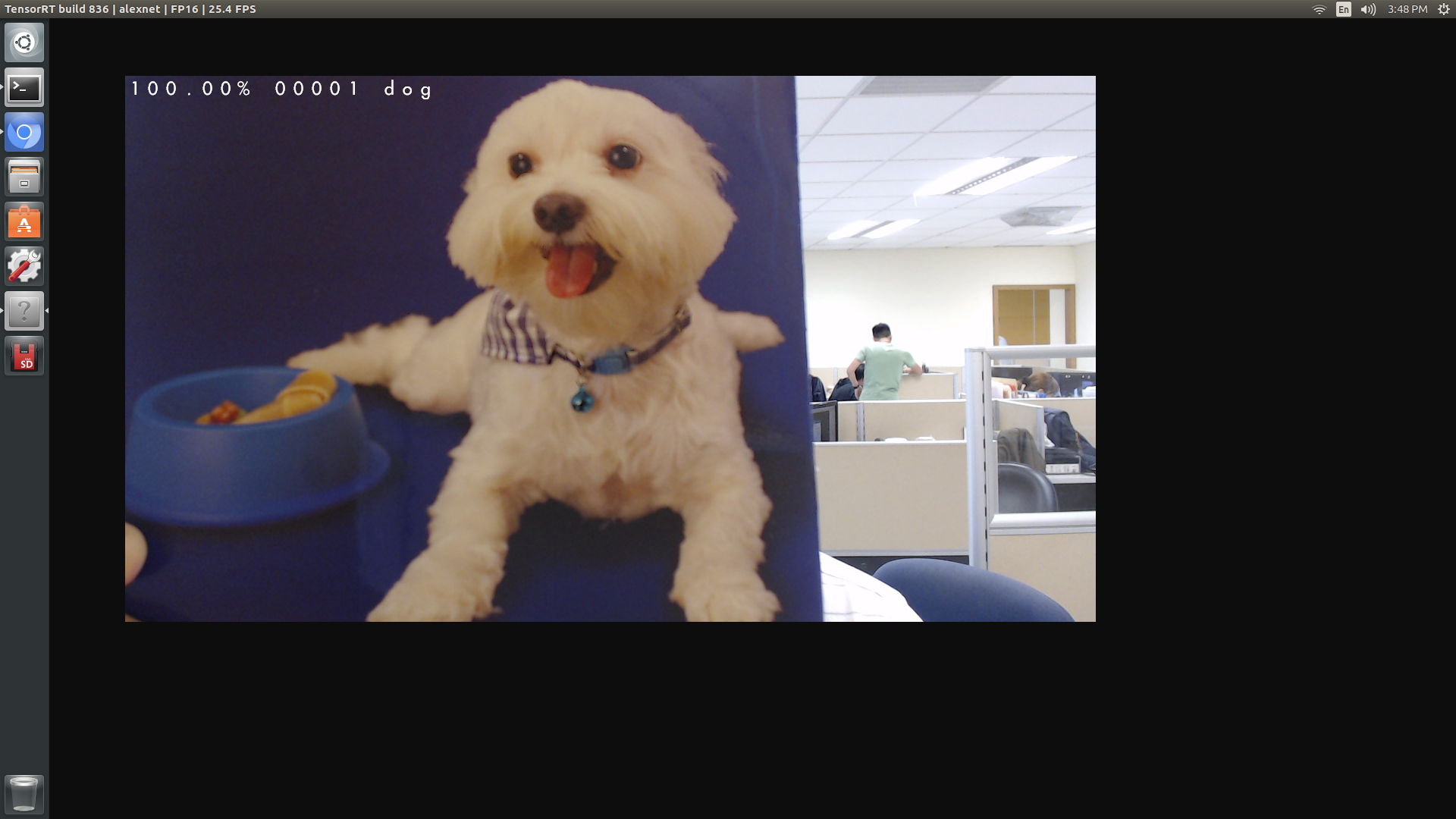
I noticed that preprocessing and mean subtraction of input images were handled differently in various implementations/tutorials of caffe models. In particular, the deeplearning-cats-dogs-tutorial code/create_lmdb.py pre-processed all input images with cv2.equalizeHist() and then calculated average pixel values for all image locations as mean.binaryproto. When I averaged out all pixel locations for mean.binaryproto, I got roughly [128, 128, 128] as mean RGB values for all images in the (cats-dogs) training dataset.
However in jetson-inference code, mean subtraction of input images was hard-coded as roughly [104.0, 112.7, 122.7] in imageNet.cpp!
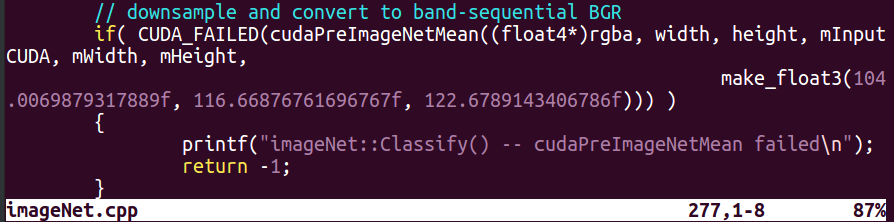
The difference of preprocessing and mean subtraction of input images between training and inferencing would likely incur some degradation in prediction accuracy. I think I’d need to fix this when using TensorRT for production.