Verifying mAP of TensorRT Optimized SSD and YOLOv3 Models
Quick link: jkjung-avt/tensorrt_demos
Mean Average Precision (mAP)
In recent years, the most commonly used evaluation metrics for object detection is “Average Precision (AP)”. As far as I know, this was first standardized in The PASCAL Visual Object Classes Challenge 2007 (VOC2007). Here is the link to VOC2007 object detection evaluation rule: 4.4 Evaluation (Detection Tasks).
In short, according to the VOC2007 detection evaluation rule, detection boxes (for a particular class of object) which have “Intersection over Union (IoU)” with a ground-truth target (of the same class) over 0.5 (but excluding duplicated detections) are counted as “true positives”, and all remaining detection boxes as “false positives”. A “precision/recall curve” is then drawn, and the precision values at recall = 0.0, 0.1, 0.2, …, 1.0 (11 points) are averaged to form the “Average Precision (AP)” (for the particular class). Once AP for each class has been calculated, we just average them to get the final “mean Average Precision (mAP)”.
Note that the definition of Average Precision has been modified as calculating the “area” (instead of the 11-point average) under the precision/recall curve since VOC2011. Refer to the picture below (courtesy of Jonathan Hui: mAP (mean Average Precision) for Object Detection).
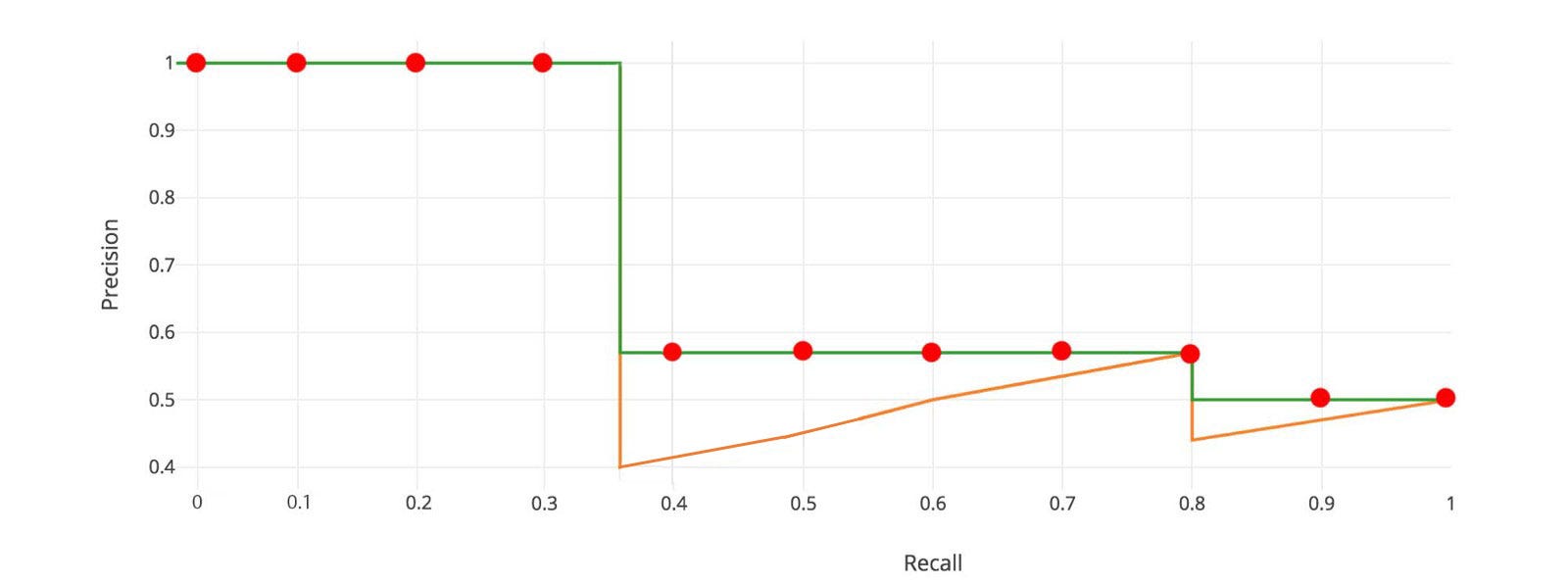
Pascal VOC (VOC2007 & VOC2012 in particular) has been a commonly used dataset for evaluating object detection models for a while. But after 2014, due to the popularity of “Microsoft Common Objects in Context (MS-COCO)” datasets, people started to pay more attention to accuracy of the bounding box locations. Instead of using a fixed IoU threshold, MS-COCO AP is averaged over multiple IoU thresholds between 0.5 (coarse localization) and 0.95 (perfect localization). More specifically, 10 different IoU thresholds are evaluated: 0.5, 0.55, 0.6, 0.65, …, 0.95.
In terms of notations, Pascal VOC mAP is frequently denoted as “mAP @ IoU=0.5”, “mAP@0.5”, or simply “mAP_50”. And COCO mAP could be referred to as “mAP @ IoU=0.5:0.05:0.95”, “mAP @ IoU=0.5:0.95”, “mAP@[0.5:0.95]” or simply “mAP”.
Note that COCO mAP is a much stricter/harder metrics than Pascal VOC mAP. So in general, COCO mAP numbers are much lower than Pascal VOC mAP. Be sure to know which mAP is being referred to when you read the literature. Current state of art of mAP@[0.5:0.95] for MS-COCO (2014 & 2017) dataset is around 48.4% or 0.484 (Reference: Object Detection in 20 Years: A Survey).
How to test mAP
The readers should refer to the official Pascal VOC and COCO web sites for how to evaluate mAP formally. For examples, here is a quote from COCO’s Detection Evaluation page.
This page describes the detection evaluation metrics used by COCO. The evaluation code provided here can be used to obtain results on the publicly available COCO validation set. It computes multiple metrics described below. To obtain results on the COCO test set, for which ground-truth annotations are hidden, generated results must be uploaded to the evaluation server. The exact same evaluation code, described below, is used to evaluate results on the test set.
For development, I myself don’t bother to upload detection results to COCO’s evaluation server. Instead, I use the COCO evaluation code, ‘pycocotools’, provided by Microsoft: cocodataset/cocoapi.
Verifying mAP of TensorRT Optimized SSD and YOLOv3 Models
After I optimized Single-Shot Multibox (SSD) and YOLOv3 COCO models with TensorRT, I wanted to verify mAP of the optimized models/engines and make sure they did not degrade significantly from the original TensorFlow/Darknet models. So I created python scripts to do that, as described in README.md and README_eval_ssd.md.
Based on TensorRT documentation, if we optimize a trained model using ‘FP32’ precision, the resulting TensorRT engine should produce exactly the same inference output as the original model. However, since I’ve done the optimization with ‘FP16’, there would be floating-point precision drop and the optimized TensorRT engines might be slightly less accurate.
More specifically, I created python scripts using ‘pycocotools’ API. And I checked mAP of both the original and the TensorRT optimized ‘ssd_mobilenet_v1_coco’ and ‘ssd_mobilenet_v2_coco’ with COCO 2017 validation data (‘val2017’).
$ python3 eval_ssd.py --mode tf ssd_mobilenet_v1_coco
$ python3 eval_ssd.py --mode trt ssd_mobilenet_v1_coco
$ python3 eval_ssd.py --mode tf ssd_mobilenet_v2_coco
$ python3 eval_ssd.py --mode trt ssd_mobilenet_v2_coco
An example output for TensorRT ‘ssd_mobilenet_v1_coco’ looked like the following:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.232
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.351
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.254
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.018
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.166
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.530
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.209
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.264
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.264
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.022
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.191
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.606
I compared the results with the mAP number posted in the TensorFlow detection model zoo. Note that the COCO mAP numbers in the model zoo were evaluated on “COCO 14 minival set”, which is different from what I was using.
| COCO mAP@[0.5:0.95] | Model Zoo | TF | TRT |
|---|---|---|---|
| ssd_mobilenet_v1_coco | 21 | 23.0 | 23.0 |
| ssd_mobilenet_v2_coco | 22 | 24.6 | 24.6 |
In addition, I made the comparison using VOC mAP metrics.
| VOC mAP@0.5 | TF | TRT |
|---|---|---|
| ssd_mobilenet_v1_coco | 35.2 | 35.2 |
| ssd_mobilenet_v2_coco | 37.3 | 37.3 |
I also checked mAP of TensorRT optimized YOLOv3 and YOLOv3-Tiny models and made comparison against the mAP numbers posted by the original author.
$ python3 eval_yolov3.py --model yolov3-tiny-416
$ python3 eval_yolov3.py --model yolov3-608
| VOC mAP@0.5 | YOLOv3 page | TRT |
|---|---|---|
| YOLOv3-Tiny (416x416) | 33.1 | 20.2 |
| YOLOv3 (608x608) | 57.9 | 66.5 |
Discussions
-
When I built TensorRT engines for ‘ssd_mobilenet_v1_coco’ and ‘ssd_mobilenet_v2_coco’, I set detection output “confidence threshold” to 0.3. And I used the resulting TensorRT engines to evaluate mAP. This would actually hurt the mAP since all low-confidence true positives would be dropped from mAP calculation. I think the common practice is to set this confidence threshold to 1e-2 or 1e-8 when evaluating mAP of an object detector.
-
mAP@[0.5:0.95] of TensorRT optimized ‘ssd_mobilenet_v1_coco’ and ‘ssd_mobilenet_v2_coco’ matched the original tensorflow models. The use of ‘FP16’ did not seem to cause degradation of detection accuracy at all.
-
mAP@[0.5:0.95] of TensorRT optimized ‘ssd_mobilenet_v1_coco’ and ‘ssd_mobilenet_v2_coco’ were higher than the numbers posted on TensorFlow detection model zoo. I think it is because I used a different dataset for validation.
-
For YOLOv3 and YOLOv3-Tiny models, I set “confidence threshold” to 1e-2 (code).
-
mAP@0.5 of TensorRT optimized YOLOv3-608 was significantly higher than what was posted on official YOLOv3 web site and paper. I think the main cause was also difference in datasets.
-
mAP@0.5 of TensorRT optimized YOLOv3-Tiny-416 was significantly lower than what was posted on official YOLOv3 web site. So I suspect my implementation (e.g. postprocessing code) of the TensorRT YOLOv3-Tiny model might have issues/bugs… (Be sure to let me know if you found the problem.)