TensorFlow/TensorRT Models on Jetson TX2
2019-05-20 update: I just added the Running TensorRT Optimized GoogLeNet on Jetson Nano post. It demonstrates how to use mostly python code to optimize a caffe model and run inferencing with TensorRT. Although it’s not for TensorFlow, I think it still serves as a great reference for people wanting to run TensorRT optimized models on the Jetson platforms.
2019-01-03 update: I’ve updated the master branch of my forked tf_trt_models to match the latest code in NVIDIA’s original repository. And I’ve been testing it with tensorflow-1.12.0 on Jetson AGX Xavier lately. The new code should mostly work on Jetson TX2 still. If you want to access my previous code which was verified against tensorflow-1.8.0 on JTX2, you could check out my tf-1.8 branch instead.
Quick link: jkjung-avt/tf_trt_models
I forked the code from NVIDIA-Jetson/tf_trt_models and developed a camera_tf_trt.py script which could do real-time object detection with TensorRT optimized models.
Background information and references
-
TensorRT Integration Speeds Up TensorFlow Inference: NVIDIA TensorRT has been integrated into TensorFlow (since v1.7.0), and the python API is extremely easy to use!
-
GTC 2018 talk: “Accelerate TensorFlow Inference with New TensorRT Integration”, video, slides
-
Announcement on Jetson TX2 developer forum: TensorFlow object detection and image classification accelerated for NVIDIA Jetson
-
NVIDIA’s tf_trt_models repository: NVIDIA-Jetson/tf_trt_models
How to set up Jetson TX2 environment before running the demo code
Refer to my GitHub repository (forked and modified from NVIDIA’s repository), and follow instructions in the ‘Setup’ section.
https://github.com/jkjung-avt/tf_trt_models
The steps are:
- Flash Jetson TX2 with JetPack-3.2.1 (TensorRT 3.0 GA included) or JetPack-3.3 (TensorRT 4.0 GA).
- Install OpenCV 3.4.x.
- Install TensorFlow 1.8.0. Use this pip wheel for JetPack-3.2.1, or this pip wheel for JetPack-3.3. Refer to the ‘Observations’ section below for more information about tensorflow version related issue.
- Clone the code from my GitHub repo.
- Run the installation script.
Description of camera_tf_trt.py
- The
camera_tf_trt.pyscript supports video inputs from one of the following sources: (1) a video file, say mp4, (2) an image file, say jpg or png, (3) an RTSP stream from an IP CAM, (4) a USB webcam, (5) the Jetson onboard camera. In case of image file, the script would do inferencing using the same image over and over again. - The object detection models all come from TensorFlow Object Detection API. Based on NVIDIA’s code, this script could download the pretrained model snapshot (provided by Google) and optimize it with TensorRT (when
--buildoption is specified). The TensorRT optimized model/graph would be automatically saved as a protobuf file in one of the./data/*directories. So the--buildaction only needs to be done once for each model to be used. Later invocations of the script could load the optimized graph directly and thus saves execution time. -
Here is the help message of the script.
$ python3 camera_tf_trt.py --help usage: camera_tf_trt.py [-h] [--file] [--image] [--filename FILENAME] [--rtsp] [--uri RTSP_URI] [--latency RTSP_LATENCY] [--usb] [--vid VIDEO_DEV] [--width IMAGE_WIDTH] [--height IMAGE_HEIGHT] [--model MODEL] [--build] [--tensorboard] [--labelmap LABELMAP_FILE] [--num-classes NUM_CLASSES] [--confidence CONF_TH] This script captures and displays live camera video, and does real-time object detection with TF-TRT model on Jetson TX2/TX1 optional arguments: -h, --help show this help message and exit --file use a video file as input (remember to also set --filename) --image use an image file as input (remember to also set --filename) --filename FILENAME video file name, e.g. test.mp4 --rtsp use IP CAM (remember to also set --uri) --uri RTSP_URI RTSP URI, e.g. rtsp://192.168.1.64:554 --latency RTSP_LATENCY latency in ms for RTSP [200] --usb use USB webcam (remember to also set --vid) --vid VIDEO_DEV device # of USB webcam (/dev/video?) [1] --width IMAGE_WIDTH image width [1280] --height IMAGE_HEIGHT image height [720] --model MODEL tf-trt object detecion model [ssd_inception_v2_coco] --build re-build TRT pb file (instead of usingthe previously built version) --tensorboard write optimized graph summary to TensorBoard --labelmap LABELMAP_FILE [third_party/models/research/object_detection/data/msc oco_label_map.pbtxt] --num-classes NUM_CLASSES number of object classes [90] --confidence CONF_TH confidence threshold [0.3]
Examples of using the camera_tf_trt.py script
Example #1: build TensorRT optimized ‘ssd_mobilenet_v1_coco’ model and run real-time object detection with USB webcam.
$ python3 camera_tf_trt.py --usb \
--model ssd_mobilenet_v1_coco \
--build
Example #2: verify the optimized ‘ssd_mobilenet_v1_coco’ model with NVIDIA’s original ‘huskies.jpg’ picture.
$ python3 camera_tf_trt.py --image \
--filename examples/detection/data/huskies.jpg \
--model ssd_mobilenet_v1_coco
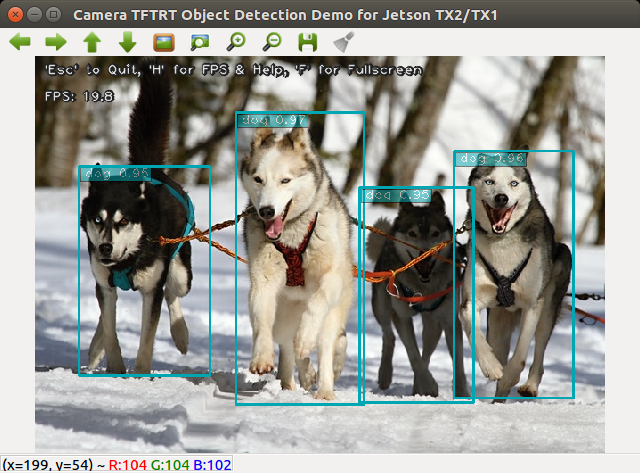
Example #3: build TensorRT optimized ‘ssd_inception_v2_coco’ model and run real-time object detection with Jetson onboard camera.
$ python3 camera_tf_trt.py --model ssd_inception_v2_coco \
--build
Example #4: test the optimized ‘ssd_inception_v2_coco’ model with a mp4 video file.
$ python3 camera_tf_trt.py --file \
--filename test_video.mp4 \
--model ssd_inception_v2_coco
Observations
-
I first tested tf_trt_models code with tensorflow-1.10.x and tensorflow-1.9.0 pip wheel files provided by NVIDIA. That did not work too well. There were several problems. First, loading SSD models and optimizing the models with TensorRT ran very slowly (>10 minutes). Secondly, tensorflow kept reporting errors like the following ones.
... E tensorflow/contrib/tensorrt/log/trt_logger.cc:38] DefaultLogger Parameter check failed at: ../builder/Network.cpp::addInput::364, condition: isValidDims(dims)or
... E tensorflow/contrib/tensorrt/log/trt_logger.cc:38] DefaultLogger cudnnFusedConvActLayer.cpp (64) - Cuda Error in createFilterTextureFused: 112019-05-24 update: Thanks to Dariusz, who provided his finding in Disqus below, I now have a solution to “extremely long model loading time problem” for the newer versions of tensorflow. Please refer to my new blog post TensorFlow/TensorRT (TF-TRT) Revisted for details.
-
Documentation in NVIDIA’s original repository did ask users to install tensorflow-1.8.0. When I switched to tensorflow-1.8.0, all the problems mentioned above were gone! Since NVIDIA only officially provided tensorflow-1.8.0 pip wheel files for JetPack-3.2.1 (TensorRT 3.0 GA), I ended up compiling tensorflow-1.8.0 against JetPack-3.3 (TensorRT 4.0 GA) by myself. I’ve shared the pip wheel file in the ‘How to set up Jetson TX2 environment’ section above.
-
When deploying ‘ssd_inception_v2_coco’ and ‘ssd_mobilenet_v1_coco’, it’s highly desirable to set
score_thresholdto 0.3 (or other sensible values) in the config file (reference). By doing that, the computations in NonMaximumSuppression were reduced a lot and the model ran much faster. Testing with tensorflow-1.8.0 on my Jetson TX2, after I set thescore_thresholdto 0.3, the models indeed ran as fast as what NVIDIA has published! -
‘ssd_mobilnet_v2_coco’ could not be tested since the model config file and its checkpoint file do not match. I’d post an update if I find a way to fix it.
Otherwise I plan to test out more pretrained object detection models (including, say, Faster R-CNN ones) from TensorFlow detection model zoo. Hopefully, I will be able to share more experience on that soon.
Do feel free to leave a comment below.