Speeding Up TensorRT UFF SSD
Quick link: jkjung-avt/tensorrt_demos
In my previous post, I explained how I took NVIDIA’s TRT_object_detection sample and created a demo program for TensorRT optimized SSD models. The resulting optimized ‘ssd_mobilenet_v1_coco’ ran as fast as ~22.8 frames per second (FPS) on Jetson Nano. However, there was this “#TODO enable video pipeline” comment in NVIDIA’s original code. I thought about it and realized the FPS could be improved if I create a pipeline to parallelize the tasks of video input acquisition, TensorRT inferencing and video displaying. I went on and implemented the video pipeline. As a result, the above mentioned model could now run at ~26 FPS on Jetson Nano, which is pretty good improvement over the non-pipelining version.
Let me explain my implementation of video pipeline for the TensorRT UFF SSD demo in this post.
Reference
- TensorRT UFF SSD
- PyCUDA MultiThreads example
- Threading and Condition Object of Python
How to Run the Demo
Please follow my previous blog post, TensorRT UFF SSD. Make sure to install all requirements and build the TensorRT engines for testing.
Then, follow step 4 in Demo #3: Demo and run trt_ssd_async.py. For example,
$ cd ${HOME}/project/tensorrt_demos
$ python3 trt_ssd_async.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \
--model ssd_mobilenet_v1_coco
Observe that FPS number would hover around 25~26 when the code runs on Jetson Nano.
Multithreads programming with PyCUDA
If you do a diff between async (trt_ssd_async.py) and non-async (trt_ssd.py) version of the code, you’d see that a large chunk of the code are identical. What I’ve essentially done in the async code is to move “input image acquisition and TRT SSD model inferencing” into a child thread.
One key thing to note when moving pycuda related code to child thread is: “CUDA context” needs to be created inside the thread which runs the CUDA kernels or TensorRT engines. You could refer to the PyCUDA MultiThreads example for how that should be done. In case this is not done correctly, TensorRT would throw out some very obfuscated error!! Reference: TensorRT do_inference error
[TensorRT] ERROR: CUDA cask failure at execution for trt_volta_scudnn_128x32_relu_small_nn_v1.
[TensorRT] ERROR: cuda/caskConvolutionLayer.cpp (256) - Cuda Error in execute: 33
[TensorRT] ERROR: cuda/caskConvolutionLayer.cpp (256) - Cuda Error in execute: 33
If you take a look at my implementation, I put all CUDA context related code in the TrtThread.run() function.
Synchronization between main and child threads
Once I decided to use a child thread to get input image and do inferencing, and to use the main thread to draw detection results and display video, one major design problem I need to solve is “synchronization” between the threads. The child and main threads should run in the conventional “Producer vs. Consumer” model. The child thread produces images and detection results, while the main thread consumes them by displaying on screen. After studying all available synchronization primitives available in python3 threading module, I chose Condition Variable (Condition Object) for this task.
Traditionally, we would use a queue to manage items between the producer and the consumer. In my case, I know the child thread (producer) would take much longer to process the task. So if I were to use a queue, the maximum number of items in queue would only be 1. In regard of this, I just used a set of global variables/references to pass images and detection results from the child thread to main. Here is the relevant code:
......
# shared global variables
s_img, s_boxes, s_confs, s_clss = None, None, None, None
......
# in the child (producer) thread
while self.running:
img = read image from camera/file
boxes, confs, clss = TRT SSD model inferencing on img
# Update the global variables while grabbing condition lock, then
# notify main (consumer) thread about availability of the new image
# and detection result.
with self.condition:
s_img, s_boxes, s_confs, s_clss = img, boxes, confs, clss
self.condition.notify()
......
# in the main (cunsumer) thread
while True:
with condition:
# Wait for notification from the child (producer) thread
condition.wait()
# Copy over references to the image and detection result
# while holding condition lock.
img, boxes, confs, clss = s_img, s_boxes, s_confs, s_clss
draw and display with (local) img, boxes, confs, clss
......
Fitting it together
Based on the above-mentioned design, the child and main threads work a producer and a consumer. To view it from another angle, we could also say the 2 threads work in a pipeline fashion. The child thread grabs a “new” image frame for processing/inferencing, while the main thread works on the “previous” image frame and detection result at the same time. And this continues on.
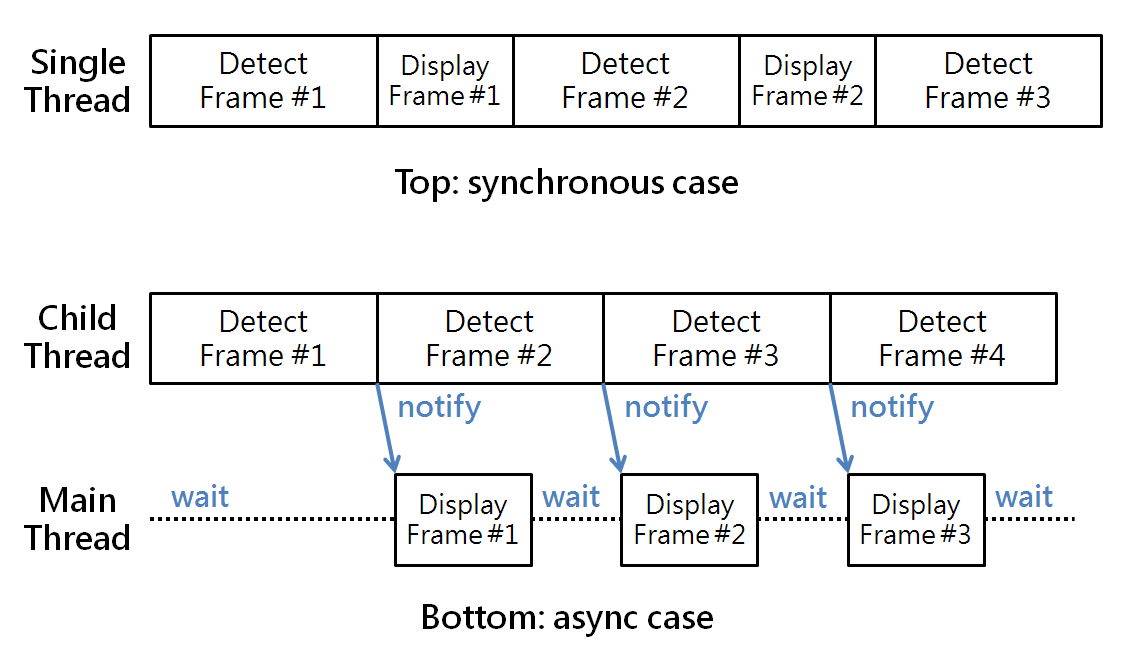
As a result of this “async” or video pipelining design, I’m able to bump up FPS from 22.8 to ~26 when testing TensorRT optimized ‘ssd_mobilenet_v1_coco’ on Jetson Nano. Furthermore, a reader, mbufi told me that the code also works great on Jetson AGX Xavier.
I have confirmed SSD works with Xavier and is running at 130FPS using async!! Amazing.
Discussion
-
Python multithreading works best if most of the tasks are “I/O bound” (not limited by the “GIL”). In our case, TensorRT inferencing (mostly handled by CUDA driver) are considered as I/O operations. NVIDIA has implemented ‘tensorrt’ and ‘pycuda’ modules well so they don’t hold the GIL while executing CUDA kernels. That’s key to why this design of
trt_ssd_async.pyworks. -
If we seek the highest throughput (FPS) of TRT SSD detection, we might go the extreme and “only do TensorRT engine inferencing in the child thread”. That is, we do all of input image acquisition, pre-processing and detection output post-processing in the main thread, and let the child thread focus on CUDA and TensorRT calls only. However, I think that will make the code hard to read and maintain. I choose not to do that.
-
NVIDIA’s original sample also has this comment in the code: #TODO using pyCUDA for preprocess. It hinted that one more way to further optimize the code is to do image preprocessing with GPU/CUDA. The preprocessing should include resizing (300x300), converting ‘uint8’ to ‘float32’, normalization and mean subtraction.
-
The same “async” or video pipelining trick could also be applied to my earlier TensorRT demo examples: “Demo #1: GoogLeNet” and “Demo #2: MTCNN”. In fact, I’ve implemented trt_googlenet_async.py for Demo #1. Check it out if you are interested.
-
Following up fro the previous point, we could actually improve throughput (FPS) of “Demo #2: MTCNN” even more by creating a more granular pipeline such as: input/preprocessing -> PNet -> RNet -> ONet -> output. More on that later, probably…