DQN (RL Agent) on TX1 for Nintendo Famicom Mini
I’ve had some conversation with a few friends about my endeavor to train a reinforcement learning (RL) agent to play Nintendo games. What I found was that few people really understand the RL part. So I think it’d be good if I elaborate on it a little bit.
I’d start by borrowing the following slide from David Silver’s presentation. David Silver is one of the lead developers at Google DeepMind. He co-authored DeepMind’s paper on a general AI agent to play Atari games, which I also cited in my earlier post.
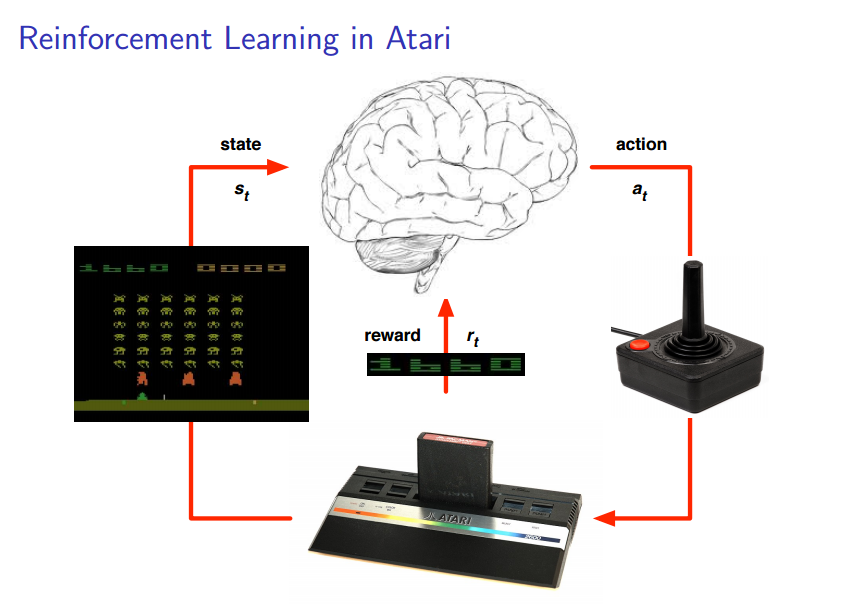
courtesy of http://www0.cs.ucl.ac.uk/staff/d.silver/web/Resources_files/deep_rl.pdf
What I’m trying to do is similar to DeepMind’s Atari RL agent. I want to train the same AI agent to play on, instead of a software emulator, a real Nintendo console.
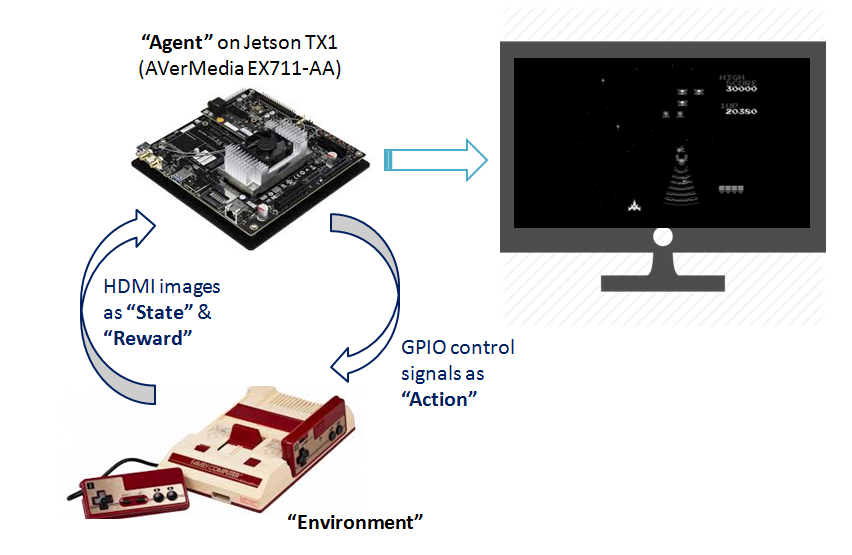
- The RL agent is a Torch7 program running on Jetson TX1.
- The environment is the game presented by the physical Nintendo Famicom Mini console. I’ve chosen the ‘Galaga’ game to work with first.
- Nintendo Famicom Mini outputs HDMI video to TX1. The RL agent can extract from the HDMI video both the ‘state’ (game image) and the ‘reward’ (game score, number of remaining lives, etc.).
- On ther hand, the RL agent takes ‘actions’ (moving left/right or firing bullets) by altering TX1 GPIO signals, which would be hooked up to the joystick of Nintendo.
- The goal of the RL agent is to ‘maximize the score of the game (the reward)’. It learns that by exploring different states/actions and looking at the reward signals. Whenever it gets a positive reward, it knows that it has done something right in the previous state/action sequence, and it shall take the same action if it encounters similar state sequence again. In this way the RL agent gets to play the game better and better over time.
I’ve been calling this ‘RL agent’ as ‘AI agent’, ‘DQN’ or ‘Deep Q Learner’ interchangeably, because the reinforcement leanring (RL) agent is indeed an aritificial intelligence (AI) agent which is implemented by a Deep Neural Network approximator of Q-functions. I can probably explain Q-functions (of reinforcement learning) better in another later post. But here is how it looks like for the Nintendo/Atari game agent. This diagram is from the original Nature’s paper by DeepMind.

- In the diagram, input to the Deep Neural Network is raw image of the game (‘state’), and output are ‘Q-values’ of all possible ‘actions’.
- The Deep Neural Network consists of a couple of Convolutional Layers, which are efficient for processing images.
- A “Q-value” measures how good it is to take a particular ‘action’ in current ‘state’. So when the RL agent has learned how to play the game (i.e. has learned a good ‘Q-value’ approximator), it would subsequently pick every time the action with the highest estimated ‘Q-value’ in order to maximize its score.
- The learning process involves updating Neural Network weights based on ‘temporal difference (TD)’ updates on the ‘Q-values’.
Hopefully this post helps to clarify RL and DQN a little bit…