Multi-threaded Camera Caffe Inferencing
2019-05-16 update: I just added the Installing and Testing SSD Caffe on Jetson Nano post. If you are testing SSD/caffe on a Jetson Nano, or on a Jetson TX2 / AGX Xavier with JetPack-4.2, do check out the new post.
Quick link: tegra-cam-caffe-threaded.py
A while ago, I wrote the post Capture Camera Video and Do Caffe Inferencing with Python on Jetson TX2. I was subsequently asked whether I could post another example code to do camera capturing and caffe inferencing in 2 different threads. I did spend some time and develop an python script accordingly. As usual, I shared the code on my Gist repository (refer to the “quick link” above).
I think the code in this new tegra-cam-caffe-threaded.py script is mostly straightforward. However, there are some design considerations worth mentioning. And thus I decided to write a post about it.
Design consideration #1: how to divide the work between the 2 threads
I have prior experience in multi-threaded python scripts which do both camera image capturing and caffe inferencing. What I’ve found is that I had to initialize caffe and do caffe inferencing in the same thread, otherwise caffe inferencing would not behave properly (more specifically, caffe.set_mode_gpu() would not work and caffe kept running very slowly in CPU mode). So when I wrote this tegra-cam-caffe-threaded.py code, I decided to only move camera image capturing part to a sub-thread, and let the main thread do all rest of the work, including caffe initialization, inferencing and image rendering.
Here’s the code snippet for initiating the sub-thread to do camera image capturing and for terminating it when done.
import threading
#
# This 'grab_img' function is designed to be run in the sub-thread.
# Once started, this thread continues to grab new image and put it
# into the global IMG_HANDLE, until THREAD_RUNNING is set to False.
#
def grab_img(cap):
global THREAD_RUNNING
global IMG_HANDLE
while THREAD_RUNNING:
_, IMG_HANDLE = cap.read()
def main():
......
# Start the sub-thread, which is responsible for grabbing images
THREAD_RUNNING = True
th = threading.Thread(target=grab_img, args=(cap,))
th.start()
......
# Terminate the sub-thread
THREAD_RUNNING = False
th.join()
Design consideration #2: synchronization between the 2 threads
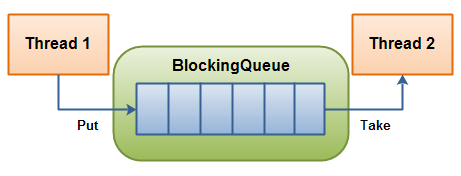
Our multi-threaded camera caffe code actually fits into the classical producer-consumer model, as illustrated in the diagram below (courtesy of howtodoinjava.com).
{kind=link}
The camera image capturing thread would act as the producer, while the main (caffe inferencing) thread the consumer. In such a producer-consumer model, we would normally design a queue to decouple the production and consumption of items, i.e. captured image frames in our case. This way we would not need to worry about matching the rate of the production and consumption. We could simply monitor fullness of the queue to decide whether we need to drop items or throttle the consumer.
In our case, I thought the producer (camera capturing, at 30 fps) was likely running faster than the consumer (caffe inferencing, for which the rate would depend on how complicated the caffe model was). So I didn’t really need to implement the queue in-between. Instead, I only needed to keep track of the latest image frame produced by the camera capturing thread. By taking advantage of the garbage collector in python, I didn’t even need to use a mutex to protect the reference to the kept (latest) frame.
I used a single global variable IMG_HANDLE to reference the image frame. This IMG_HANLDE gets updated every time the producer (camera capturing thread) gets a new frame from the camera. On the other hand, whenever the consumer (caffe inferencing thread) is ready to process the next image frame, it just dereferences IMG_HANDLE and thus always gets the latest image frame. I think this is what happens when we run the code.
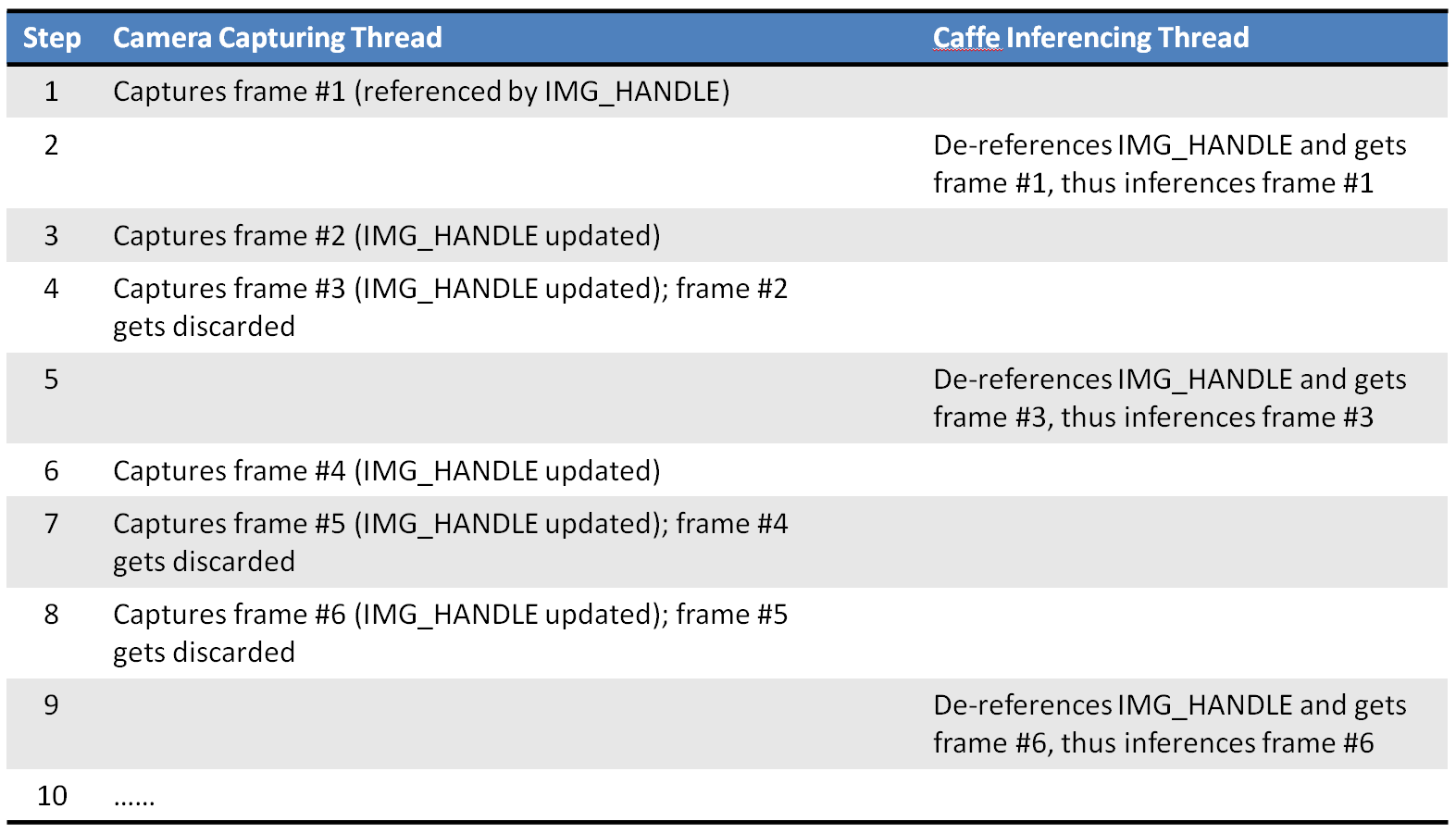
So, what happens to frames #2, #4, and #5, when they get discarded? You might ask.
I think they get garbage-collected by python since there is no reference to them any more in the program. In fact, frames #1, #3 and #6 also get garbage-collected once the caffe inferencing thread finishes processing them (and no longer keeps any reference to them).
How to run the code
Please refer to my previous post Capture Camera Video and Do Caffe Inferencing with Python on Jetson TX2. Make sure all “Prerequisite” has been done on the target JTX2 platform. Then run the code exactly the same way as the old tegra-cam-caffe.py script.
$ python3 tegra-cam-caffe-threaded.py --usb --vid 1
Discussion and conclusion
Let’s consider one question. Does this multi-thread design help to improve throughput of our caffe inferencing script? That is, would we be able to inference more frames per second (fps) with this design (maybe because the main thread does not need to block for the next camera frame to arrive)?
My answer is “most likely not”. Say, in the original single-threaded design, assuming the camera image capturing part (the producer) generates image frames faster than the caffe inferencing part (the consumer) processes them. Then the cap.read() calls would always return immediately (without any blocking), since there are always image frames ready for processing. More specifically, the old image frame gets queued in either V4L2 driver buffers or gstreamer/opencv stack and gets returned by cap.read() immediately. And that old image frame is likely not the latest frame grabbed by the camera…
So, what’s the real benefit of making this multi-threaded design?
In our tegra-cam-caffe-threaded.py, we only keep “the latest one” image frame in the global variable IMG_HANDLE. So the caffe inferencing (main) thread always gets the latest grabbed image frame for processing. In conclusion, I’d say this multi-threaded design helps to improve latency of the caffe inferencing program.