Capturing HDMI Video in Torch7
I need to capture HDMI video from Nintendo Famicom Mini and convert the video data to Torch Tensors, so that I can train DeepMind’s DQN AI agent to play real Nintendo games. Ideally this video capture module should not consume too much CPU and should produce image data with low latency.
I know quite a few options for capturing HDMI video on Tegra X1 platforms (some of which might require installation of custom device drivers):
- AVerMedia’s C353 HDMI/VGA frame grabber.
- HDMI video inputs on AVerMedia’s EX711-AA TX1 carrier board.
- ZHAW’s HDMI2CSI adapter board.
- Magewell’s USB Capture HDMI.
- Inogeni’s HD to USB 3.0 Converter.
I end up choosing option #2 because I have AVerMedia’s EX711-AA carrier board on hand and it can take HDMI video input without connecting any additional adapter board (quite convenient).
The HDMI video inputs (HDMI-to-CSI) on EX711-AA carrier board are implemented as V4L2 devices and are exposed as /dev/video0 and /dev/video1. Since performance (CPU consumption and latency) is a major concern, I think it’s a good idea to write most of the video data handling code in C. And I’d use Lua FFI library to interface between my C code and Torch7/Lua code.
More specifically I have implemented my Torch7 video capture module this way:
- In the C code I call V4L2 API to fetch video data from /dev/video0 directly. This minimizes overhead, comparing to GStreamer or libv4l, etc.
- HDMI video from Nintendo Famicom Mini is RGB 1280x720 at 60 fps. To reduce the amount of video data for DQN to process, I’d decimate video data to grayscale 640x360 at 30 fps only. I do this video data decimation in C code as well.
- Passing video data from C code to Torch7/Lua through FFI interface is straightforward. I referenced Atcold’s torch-Developer-Guide for the actual implementation.
- Raw video data from /dev/video0 is in UYVY format. The above-mentioned video data decimation process would throw away U and V, as well as 3/4 of Y values. The resulting grayscale image data is ordered, pixel-by-pixel, from left to right, then from top to bottom.
- The decimated grayscale image data (640x360) would correspond to data layout for a ByteTensor(360,640,1), or ByteTensor(H,W,C), where H stands for height, W for width and C for number of color channels. However, Torch7 image and nn/cunn libraries expect image data in the form of ByteTensor(C,H,W). So after getting image data (img) in Torch7 through FFI, I’ll have to do
img:permute(3,1,2)to format it in the right order. Then I can useimage.display()to show the images correctly.
The resulting code is located in my dqn-tx1-for-nintendo repository and manifested in these files:
vidcap/Makefile
vidcap/device.h
vidcap/device.c
vidcap/video0_cap.c
vidcap/vidcap.lua
test/test_vidcap.lua
The following screenshot was taken when I ran qlua test/test_vidcap.lua on the EX711-AA TX1 carrier board, with Nintendo Famicom Mini connected to /dev/video0 input.
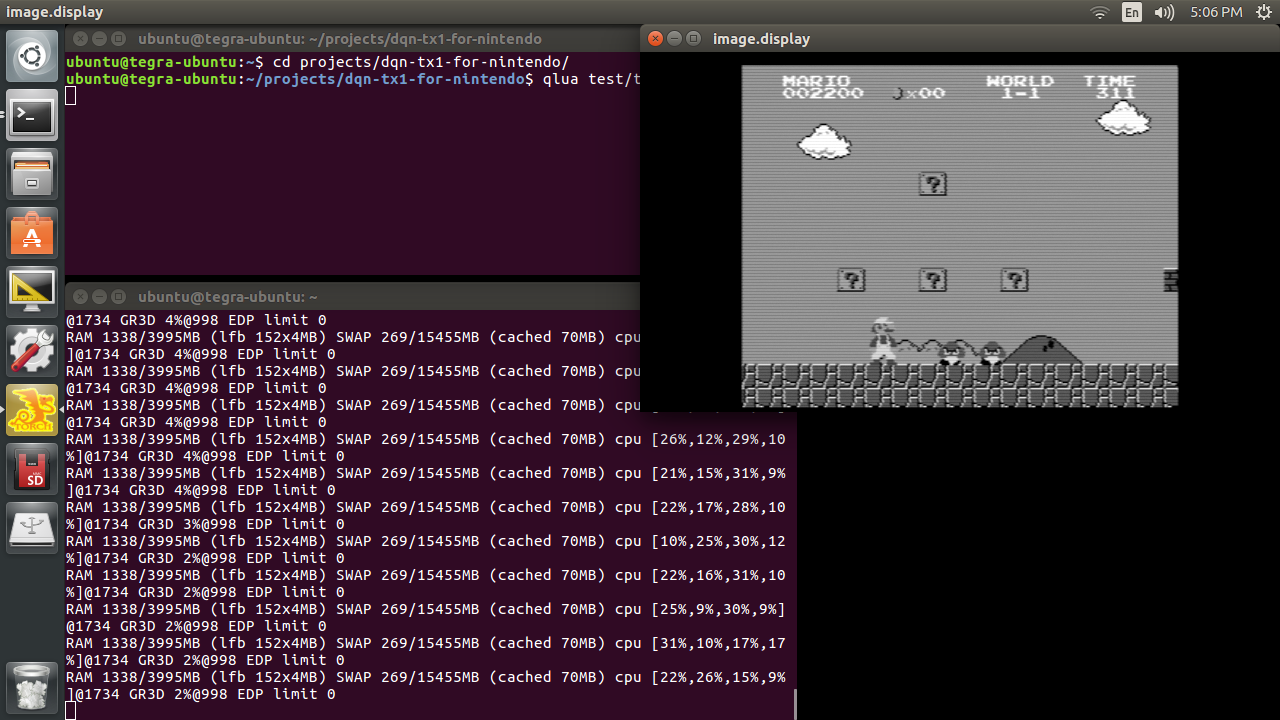
From the screenshot, I observed that CPU loading for test_vidcap.lua was around 20% accross all 4 CPUs of TX1. That was after I ran the ‘jetson_clocks.sh’ script to boost all CPUs of TX1 to the highest clock rate. Note that capturing 1280x720p60 video and rendering at 30 fps continuously does take a tow on the TX1 system. I don’t consider 20% CPU consumption ideal but it’s probably OK. I should have enough remaining CPU power to run the DQN. On the other hand I also verfied latency of the captured grayscale image data by playing a few games off it. The result seemed satisfactory.
As mentioned in my earlier post, there is memory leak in image.display(). The ‘test_vidcap.lua’ script also suffers from the same problem and could hog more and more memory over time.
To-do:
- Primer on V4L2 API.