Kaggle 2018 Google AI Open Images - Object Detection Track
Quick link: keras-yolo3
Kaggle just held the “Google AI Open Images - Object Detection Track” competition from July 4 to August 30. I particiated, and finished at the 86th spot (bronze zone). I was disappointed with this result. But anyway I’d like to share how I approached the competition and what I’ve learned from it.
The Kaggle “Google AI Open Images - Object Detection Track” competition was quite challenging because:
- The dataset was huge. There were 1,743,042 images with 12,195,144 bounding boxes in total (reference). And the total size of the training images was over 500GB.
- Time was very limited. The whole period of the competition was less than 2 months.
- The total number of classes (500 classes) was rather large for object detection models, while distribution of classes was inbalanced (reference).
In the past, I’ve been focusing on building fast object detector on embedded platforms (JTX2). When I learned about thie competition, I immediately wanted to join because I’d also like to hone my skills on building more sophiscated object detection models which could detect more objects and with higher accuracy. Mostly occupied by work, I only managed to start working on the competition around Aug. 11, less than 3 weeks remaining from end of the competetion.
My Thought Process While Working on The Competetion
- I didn’t want to use TensorFlow Object Detection API, because I thought a lot of people would be using it. It’d be difficult to differentiate my results if I also did that.
- I needed something which could generate training data from the original jpg files directly. Converting training data to LMDB or other formats might take up too much HDD space for me.
- YOLO was probably a good choice, since it has been shown that YOLO could be used to detect many classes of objects. (YOLOv2, or YOLO9000, could detect 9,000 difference classes of objects.)
I ended up choosing to use the Keras YOLOv3, qqwweee/keras-yolo3, to implement my object detector for the competition.
My Approach to The Problem
- Developed the script,
openimgs_annotation.py, to convert Open Images annotations into YOLOv3 format. -
Used Learning Rate Finder (LRFinder) to search for best learning rates for the model. I set learning rates to cycle between 1e-9 and 3e-4, after plotting LRFinder output as below.
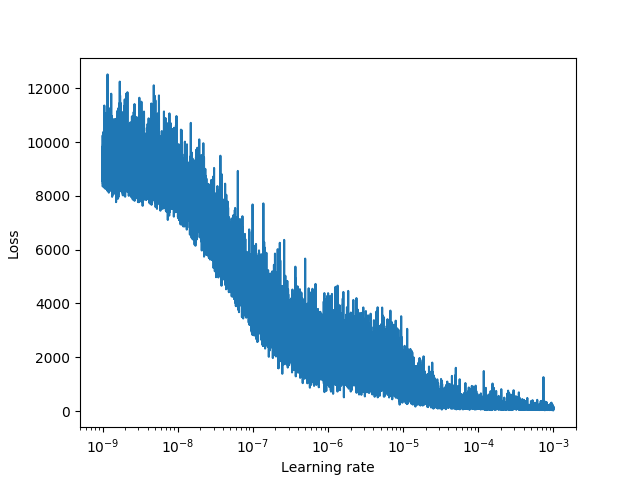
-
Used Cyclic Learning Rate (CLR) as an attempt to train the best possible weights for the model. Here’s how my learning rate schedule looked like:
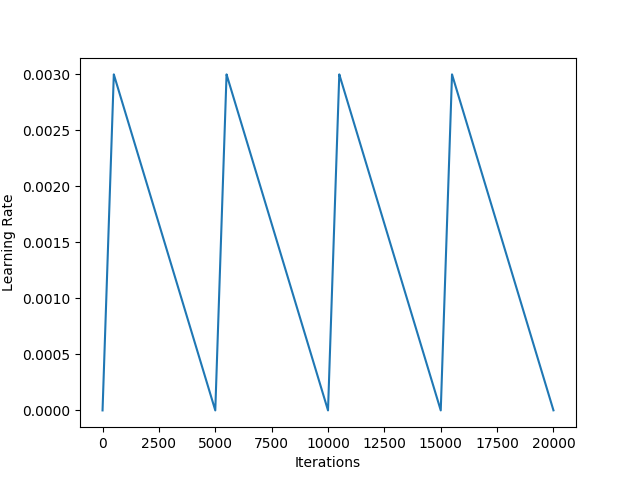
I did not do more analysis on the dataset, nor did I try to increase capacity (depth/width) of the YOLOv3 model. I simply modify the model with 500 class outputs. I first trained the model with Adam optimizer and with the CNN feature extraction layers freezed for a few (3) epochs. I then kept training the model with Adam optimizer but with all layers unfreezed for a few (3) epochs. Finally I used CLR to fine-tune the model for as long as time permitted.
What I’ve Found Out or Learned
- I only had 1 GeForce GTX-1080Ti GPU for training my Keras YOLOv3 model. It took ~35 hours for me to train the model for 1 epoch. Since I started very late, I was only able to train my model for roughly 10 epochs in total before the final deadline. That was really not enough time for the model to learn.
- TensorFlow Object Detection API provided models already trained with open Images dataset (but with different annotation file). According to some sharing on the Kaggle discussion forum, a score of mAP 0.18 could be achieved directly from those pre-trained weights. In retrospect, it might have been easier to get a better score if I chose to start with such pre-trained weights.
- I started too late. I spent roughly a week to modify code to make sure the model could be trained with the target dataset, as well as to verify the code could produce the correct output file (for Kaggle submission).
- I used a new model (for myself) to work on the problem. I had no idea about what hyper-parameter settings would produce good results, and I did not have enough GPU resources or enough time to experiment. If possible, I should start with something I’m more familiar with when working on my next Kaggle competition.
- Other participants of the competition have done analysis on the dataset, and managed to come up with better-scoring approaches. For example, experience sharing of the 15th place could be found here, and the 19th place here. Dealing with inbalanced classes was really needed to get a better score in this competition.
Conclusion
I started late and was not able to find enough time to work on the problem. I finsihed with a mAP of 0.16889 (86th place) in this competition.

I learned from participating in this competition and would like to share the full source code I used for the competition. I do hope to find time to participate in another Kaggle competition soon. Here is the link to my GitHub repo of the source code.
https://github.com/jkjung-avt/keras-yolo3
The #1 team of this competition scored over 0.58, which I think was amazing! As a quote from the competition host says: “We are always very impressed with the community. We’re also continually pleased to see how Kaggle Competitions serve as a great medium and vehicle through which the greater data science community can learn and develop their machine learning abilities and skills.”