Working with ImageNet (ILSVRC2012) Dataset in NVIDIA DIGITS
Recently I had the chance/need to re-train some Caffe CNN models with the ImageNet image classification dataset. I wanted to use NVIDIA DIGITS as the front-end for this training task. However I didn’t find instructions about how to work with ImageNet dataset in DIGITS’ documentation. Anyway I did some trial and error, and managed to make it work. Here is how I’ve done it.
Prerequisite:
-
You need to have access to ImageNet (ILSVRC2012) image classification dataset. The reference web links are listed below. More specifically, 2 files would be needed:
ILSVRC2012_img_train.tarfor training andILSVRC2012_img_val.tarfor validation. -
You also need to have NVIDIA DIGITS installed and running on your deep learning training PC/server. I recommend running NVIDIA DIGITS with nvidia-docker. For my training task I simply used the
nvidia/digits:latestDocker image.One thing that’s kind of important to note is that it’s highly preferable to have your DIGITS’
jobsdirectory mounted on a solid state drive (SSD) disk. Since the ImageNet dataset is huge (tens of gigabytes) and doesn’t fit in GPU memory, data would need to be frequently fetched from hard disk when you train a network with this dataset. In case you have thejobsdirectory (or more specifically, the generated LMDB files) on a regular hard drive disk, the training task would definitively thrash the hard drive. (I suspect a regular hard drive disk would not sustain with such accesses for several consecutive days.)For example, I have a directory named
/data/digits-jobswhich was mounted on one of the SSD drives on my deep learning PC. And I ran NVIDIA DIGITS with the following command:$ docker run --runtime=nvidia --name digits -p 5000:5000 -p 6006:6006 -v /data/digits-jobs:/jobs -v ~/dataset:/dataset nvidia/digits:latest
How to Create the Image Classification Dataset in DIGITS
According to DIGITS’ “Image Folder Specification” documentation, we need to have ImageNet train/val images organized in the following folder structure:
train/
├── n01440764
│ ├── n01440764_10026.JPEG
│ ├── n01440764_10027.JPEG
│ ├── ......
├── ......
val/
├── n01440764
│ ├── ILSVRC2012_val_00000293.JPEG
│ ├── ILSVRC2012_val_00002138.JPEG
│ ├── ......
├── ......
So I referenced soumith’s imagenet-multiGPU.torch about how to create the folders/files with the original tar files.
$ mkdir -p ~/dataset/ILSVRC2012
$ cd ~/dataset/ILSVRC2012
### extract train data
$ mkdir train
$ cd train
$ tar xvf ~/Downloads/ILSVRC2012_img_train.tar
$ find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
### extract val data
$ cd ..
$ mkdir val
$ cd val
$ tar xvf ~/Downloads/ILSVRC2012_img_val.tar
$ wget
https://raw.githubusercontent.com/jkjung-avt/jkjung-avt.github.io/master/assets/2017-12-01-ilsvrc2012-in-digits/valprep.sh
$ bash ./valprep.sh
As this point, you could verify you have the correct number of images for both train and val.
$ cd ~/dataset/ILSVRC2012
$ find train/ -name "*.JPEG" | wc -l
1281167
$ find val/ -name "*.JPEG" | wc -l
50000
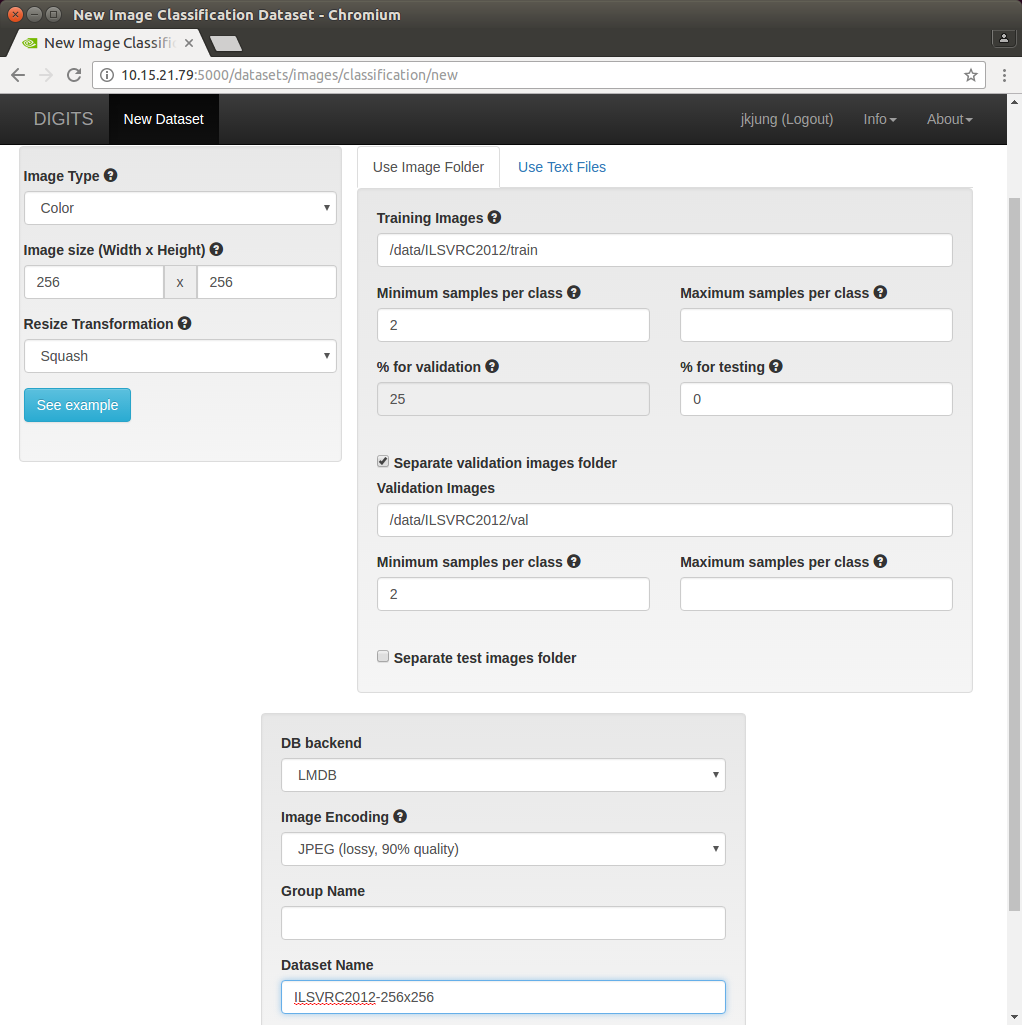
Now it’s time to fire up DIGITS and really create the LMDB dataset for training. You just go to the ‘Dataset’ tab in DIGITS and select ‘Classification’ under ‘New Dataset’. Then follow ImageNet convention by selecting Image Size 256x256 and Resize Transformation ‘Squash’. On the Image Folder side, click ‘Separate validation image folder’ and put in the pathes where your train/val images are located. As to Image Encoding, I think choosing ‘JPEG (lossy, 90% quality)’ to save disk space is the better option. Finally give the dataset a proper name and hit ‘Create’. DIGITS would then take a few minutes to process and create the dataset. Once done, you could start to train your neural network models in DIGITS with this newly created dataset.