Using cuDNN to Speed Up DQN Training on Jetson TX1
I had an idea about speeding up trainig of DeepMind’s DQN by NVIDIA’s cuDNN. Then I found out it was really easy to do that with Torch7!
All I needed to do was just to convert the neural network to ‘cudnn’ after it’s been created/loaded and cuda()’ed. More specifically, I added the corresponding code into dqn/NeuralQLearner.lua. For an explanation of cudnn.benchmark and cudnn.fastest, please refer to the official cudnn.torch page.
if self.gpu and self.gpu >= 0 then
self.network:cuda()
-- I added this part...
if self.cudnn then
cudnn.benchmark = true
cudnn.fastest = true
cudnn.convert(self.network, cudnn)
print('*** Using cudnn ***')
end
else
self.network:float()
end
In addition to cudnn, I also thought about reducing the time the DQN trainer spending on displaying game images, so that the trainer could spend more of its time doing useful training work. So I implemented that in the code too. With some trial, I picked 3 as the ‘display_freq’. That is, I let the DQN trainer display only 1 out of 3 images during training. This way, I effectively reduced CPU consumption on image display while still able to clearly see the progress of the game.
Here’s the result on Jetson TX1 after I implemented both cudnn and display_freq=3. (Note that DQN training does not really start until running for ‘learn_start (5000)’ steps.) The numbers in the table below were all obtained while the DQN was trained for Atari ‘pong’ game with TX1 CPU running at max clock frequency (sudo ~/jetson_clocks.sh).
| Test Case | Train 1000 steps | % |
|---|---|---|
| Baseline: display all frames, no cudnn | 56 s | 100 |
| Improvement #1: display 1/3 frames | 46 s | 82 |
| Improvement #2: 1/3 frames, with cudnn | 37 s | 66 |
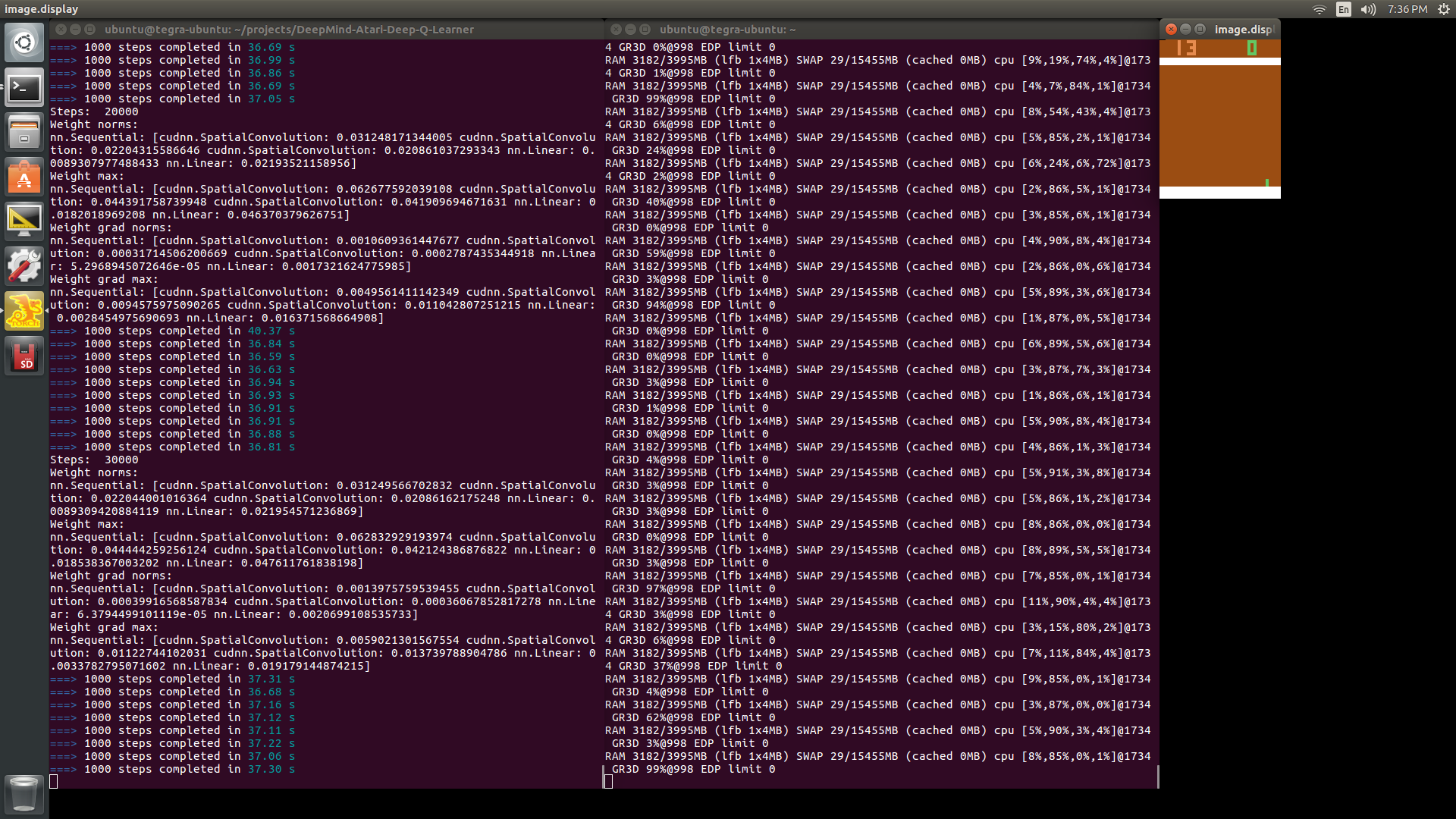
When I looked deeper at the ‘Improvement #2’ case (as shown in the screenshot below), I saw both CPU (‘cpu’ in ~/tegrastat output) and GPU (‘GR3D’) of TX1 were far away from fully loaded, while one of the 4 CPUs was constantly at ~90% loading. I think this likely indicated the bottleneck was lying in the Atari emulator (‘xitari’ and ‘alewrap’ in Lua). In other words, I think the DQN on TX1 could train much faster if the Atari emulator was able to generate game images at higher rate. Hopefully this would work out better when I train the DQN with the Nintendo Famicom Mini console.
If you’d also like to run this cudnn accelerated DQN, you can refer to my earlier post, Training DeepMind’s DQN to Play Pong. And the repository is here:
https://github.com/jkjung-avt/DeepMind-Atari-Deep-Q-Learner.